The post JINでの景品表示法への対応方法。SEOになるべく無影響での暫定案 first appeared on WebFood.
]]>景品表示法が2023年10月から改正されアフィリエイト広告を載せるブログでも対応が必要になっています。ブログテーマ「JIN」での対応方法をご紹介します。
各ASPからのメールで焦る
9月になって各ASPからメールが来て、遅ればせながら対応しなければならないことを知りました。法律をよく読むと、対象は広告主だけが対象の法律にも解釈できるのですが、ASPが対応しろと言っているのですから、提携解除されても嫌なので対応することにしました。
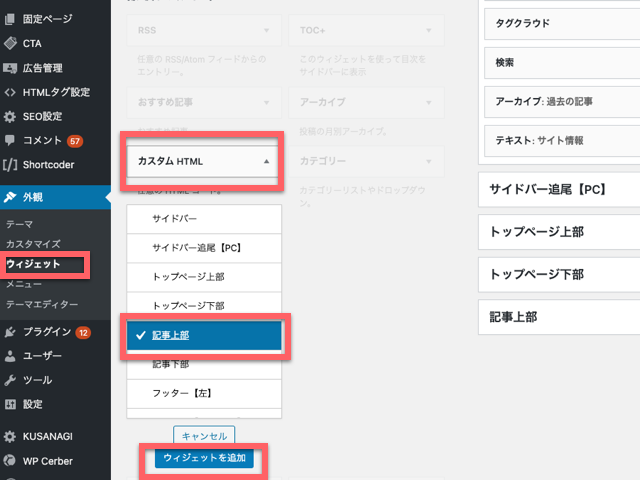
記事上のウィジェットで対応
暫定になるかもしれませんが、記事上のウィジェットに表示することで対応したいと思います。
PCだとこんな感じ。

スマホだとこんな感じ。3行になっちゃうのが嫌なのですが。
「テキスト」ではなく「カスタムHTML」で
私の場合、いまだにグーテンベルクの使い方が分からなので、昔のWidgetの画面での説明になります。同じように昔のWidgetの画面が使いたい方は「Classic Widget」というプラグインを入れると簡単に使えるようになります。
「テキスト」を使うのが普通だと思いますが、「テキスト」だとpタグが使用されてしまうので、「カスタムHTML」を使用しました。pタグはパラグラフのpです。つまり、Googleの検索エンジンが、pタグを記事の一部だと認識してしまい評価に影響を与えてしまうのを避けたかったからです。「カスタムHTML」だと、より中立的なタグであるdivタグしか使われません。記事の上部にあるので、検索エンジンが記事のタイトルやディスクリプションとして取り扱ってしまったら困りますよね。
コードが入力できます。
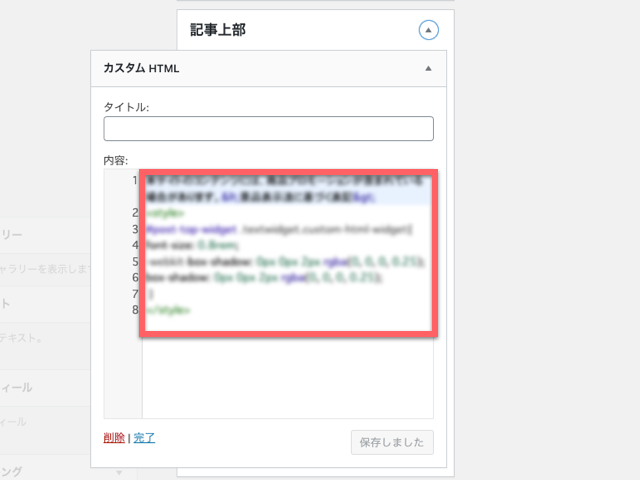
ここに入力するコードですが、一応2種類掲載しておきます。
普通にHTML内に文章を記載
まずは一つ目。普通にHTML内に伝えたい文章を記載してしまいます。
ただ、styleタグ内に記載しているCSSのコードは、「テキスト」ではなく「カスタムHTML」を使ったために適用されなかった枠線のスタイルをここで指定しています。また、本文より字は小さくて良いのでフォントサイズも指定しています。子テーマのstyle.cssに書いても良いのですが、暫定的な対応だったため、ここに記載しました。
本サイトのコンテンツには、商品プロモーションが含まれている場合があります。<景品表示法に基づく表記>
<style>
#post-top-widget .textwidget.custom-html-widget{
font-size: 0.8rem;
-webkit-box-shadow: 0px 0px 2px rgba(0, 0, 0, 0.25);
box-shadow: 0px 0px 2px rgba(0, 0, 0, 0.25);
}
</style>
スポンサーリンク
文章自体もCSSに入れちゃう
2つ目の案です。
前述したように、この注意書きはなるべく検索エンジンに認識してほしくないので、HTML内の文字列にするのではなく、CSSに
content: を使ってスタイルとして記載することにしました。これでも読者からは同じように読めます。
<style>
#post-top-widget .textwidget.custom-html-widget{
font-size: 0.8rem;
-webkit-box-shadow: 0px 0px 2px rgba(0, 0, 0, 0.25);
box-shadow: 0px 0px 2px rgba(0, 0, 0, 0.25);
}
#post-top-widget .textwidget.custom-html-widget:after {
content: "本サイトのコンテンツには、商品プロモーションが含まれている場合があります。<景品表示法に基づく表記>";
}
</style>
本サイトではこの2つ目の案のコードを採用しています。どちらもそこまで差が出るとは思いません。こちらがトリッキー過ぎると思われる方は1つ目でも大丈夫だと思います。
今後やりたい対応
この方法、最低限、法律違反しないために作った暫定的なもので、まだまだ改善の余地があります。
アフィリエイトリンクがある記事にだけ表示
前述した方法だと、全記事に表示されてしまうんですよね。でもサイト内にはアフィリエイトリンクが全くない記事も普通にあります。なので、アフィリエイトリンクがある記事にだけ表示される仕組みにしたいです。
アイディアとしては記事ごとにフラグをつけて、条件分岐で表示するという方法が考えられます。
ただ、このアイディアは膨大な記事一つ一つを見てフラグを付けていく作業が発生してしまいます。なので、記事内に、ASPのURLへのリンクがあるかを判別して自動で表示してくれる仕組みが理想です。
目次の下くらいに表示
前述した方法だと、記事のトップに表示されます。でもある程度読んでもらってからこの注意書きを読んでもらった方が、読了率が上がる気がします。
導入部分があって目次があって、その次くらいにこの注意書きがあるのがちょうど良いのではないかと思います。記事の終わり近くにあるのは流石に読者さんに対して不誠実なので。
目次を表示する部分のコードをいじれば簡単にできるとは思います。ただ、膨大な記事の中にはあえて目次を表示させないようにしている記事もあるんですよね。そのような記事もアフィリエイトリンクを含んでいたりします。
目次が無い記事の場合は、一つ目のパラグラフが終わったタイミングで表示するのが良いと思いますが、ここまで実装するのは少し面倒そうです。
この辺りの改善は、今後この法律の運用のされ方を見ながら、必要であれば対応するというようにしたいと思います。
The post JINでの景品表示法への対応方法。SEOになるべく無影響での暫定案 first appeared on WebFood.
]]>The post レバテックフリーランスさんのメディアにWebFoodが掲載されました! first appeared on WebFood.
]]>レバテックフリーランスのWEBメディアに当ブログ、WebFoodが紹介されていました。
技術のスキルアップを図りたいエンジニアにおすすめのサイトまとめ
このメディアを運営しているレバレジーズさんという会社はCMも出すくらい大きくて有名なので、かなりびっくりしましたし、素直に光栄に思いました。
また、エンジニアさん向けの記事で、IIJさんなど大きな会社の技術ブログなどとともに紹介して頂いているのも畏れ多いことです。
選ばれた理由は正直わからないのですが、エンジニア畑出身でフリーランスとしてブログで情報発信をしている点が、読者層に合っているのかもしれません。思ったよりそういうブログって少ないのかもしれませんね。
とは言え、最近はWebFoodはプログラミングなどのエンジニアさん向けの技術記事よりも、ブログライティングやビジネス寄りの記事が多くはなってきていますが。
でも、エンジニアさんもフリーランスであれば、ライティングやビジネスのスキルを身につけるのはめちゃくちゃおすすめです。
情報発信して自己ブランディングできれば、本業での報酬単価も上げることもできます。あと、単純に学んだ技術をブログに書くことって自分の勉強にもなるし、同じ問題で困ってる人のためにもなるんですよね。
技術ブログの良い例が、先ほどの記事でたくさん紹介されているので、参考にしてみてください。私も次の記事で、読まれる技術ブログの書き方を説明しています。
[card name=how-to-write-tech-blog]
The post レバテックフリーランスさんのメディアにWebFoodが掲載されました! first appeared on WebFood.
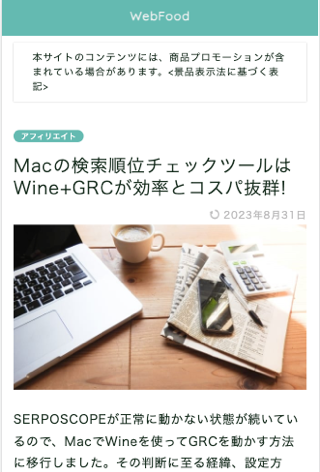
]]>The post Macの検索順位チェックツールはWine+GRCが効率とコスパ抜群! first appeared on WebFood.
]]>SERPOSCOPEが正常に動かない状態が続いているので、MacでWineを使ってGRCを動かす方法に移行しました。その判断に至る経緯、設定方法、運用してみた感想をご説明します。
Parallelsに代わるWineを発見!
Macbook Pro(2017)を自宅筋トレ中の事故で壊してしまったので、この度、M2 Macbook Airを購入しました。次の記事で説明したように、丁度Googleの仕様変更の都合でSERPOSCOPEが動かなくなってしまっていて、検索順位チェックツールを移行しようと考えていました。
[card name=serposcope-review]
SERPOSCOPEの前は、Parallels DesktopでWindowsを走らせてその上にGRCを動かすという方法をとっていました。MacBook Pro(2017)には重い処理だしメモリーも不足気味で、筐体が熱くなってしまいました。それが嫌だったのと、コスパも良くなるので、SERPOSCOPEに移行した経緯があります。
M2 Macbook Airになるとスペックは圧倒的に良くなるので、Parallels×Windows×GRC という方法でも余裕になるかと思いました。当然、SERPOSCOPEと同じように、GRCだってGoogleの仕様変更の影響を受けるはずです。なのでGRCもまともに動かない状態なのではないかと気になって調べてみたところ、全くそのような情報は出ていません。GRCは有料だし、日本では圧倒的にSERPOSCOPEよりもユーザ数が多いので、問題があれば必ず話題になっているはずです。なので現状正常に使えているということです。どのようにGoogleの仕様変更を乗り越えたかは分かりませんが、決して安くはない使用料をとっているだけありますね。
そこで、Parallels×Windows×GRCの設定を開始しようとしたら、なんと以前購入したParallels Desktop 11はM1やM2などのAppleシリコンに対応していないので、執筆時点で最新のParallels Desktop 18を購入する必要があるということがわかりました。そして、以前も使っていた無料で利用できるWindows10もAppleシリコン(正確に言うとARMアーキテクチャ)に対応していないので、ARM に対応しているWindows11を購入する必要があると言うことです。
Parallels Desktop for Mac のシステム要件
以下によると、Parallels Desktop17でも大丈夫そうですね。M1に対応していると書いてあるので。
Parallels Desktop 17 のシステム条件とサポート対象のゲスト オペレーティング システム
また、ARMに対応しているWindows10でもいける気がしますね。
とはいえ、Win10もWin11もARM版の利用は、開発者向けのWindows Insider Programを使うなど、少しトリッキーな気がするので、初心者は苦戦するかもしれません。ちゃんと調べてないのでわからないですが。
困ったなーと思いながらGRCの公式サイトを眺めていると、以下のページを見つけました。
こんなページ前からあったっけ?Wineというツールは使ったことがないのですが、名前は知っていました。でも、あまり使い物にならないイメージを勝手に持っていました。
ただ、現在の最新のMac OSにはWineが対応していないので、使えないと書いてあります。何にでも疑ってかかる私は、ほんとかなーと思いながら、M2 MacでWineが使えないか調べてみました。するとあっさり以下の@ITの記事が見つかりました。
macOSでWinアプリを実行する第3の方法、しかもWindowsのライセンスは不要です
AppleシリコンのMacで見事に秀丸というWindowsのアプリケーションを動かしています。秀丸が動いてGRCが動かない理屈はありません。
しかも、Wineにもいくつか種類があって、この記事で扱っている「homebrew-wine」はオープンソースなので完全に無料で利用できます。ということは、ParallelsとWindowsのライセンス代が浮きます。素晴らしい!
さっそくやってみました。結論から言うと問題なく動きました。GRCの公式サイトで現在は対応されていないと書いていましたが、おそらく最新の状況が反映されていないと思われます。
では、設定方法を説明していきます。
スポンサーリンク
コマンドラインでの設定はハードル高いかも
homebrew-wineはコマンドライン(エンジニアが使う黒い画面)を基本的に使うので、慣れていない方は少し抵抗があるかもしれません。でも、MacはWindowsに比べてコマンドラインを使う機会が多くなるので、この際慣れておいてもいいでしょう。(コマンドラインがどうしても嫌な方は、先ほどの記事で少し紹介されていたWineskinを使ってみるといいかもしれません。)
今回の手順で使用した環境のバージョンを記載しておきます。
| 端末 | M2 MacBook Air(2022) |
|---|---|
| Mac OS | 13.0(22A380) |
| homebrew | 3.6.17 |
| wine-crossover | 22.0.1 |
| GRC | 5.65.274.1 |
ちなみに、homebrewもエンジニアがよく使うツールで、Macのアプリケーションのインストール、バージョン管理、アンインストールなどをコマンドラインでできるようにするものです。以下の記事で詳細に説明されています。
Homebrewとは?本質的な価値を解説。何ができる?メリットは?
ここからは、先程紹介した@ITの記事の方法で、Homebrewとhomebrew-wineがインストールされている前提で説明してきます。それ以降の手順も近いですが、秀丸とGRC の違いが大きいので、詳しく手順を説明していきます。
まずはGRCの公式サイトから、通常通りGRCsetup.exeというインストールファイルをダウンロードします。
ちなみに、GRCは課金していない段階でもある程度は使うことができるので、まだ迷っている方も、課金する前にこの方法を試してみてもいいかもしれません。
ここからはコマンドラインでの作業です。Macに最初からインストールされている「ターミナル.app」などのコマンドラインを扱うアプリケーションを開きます。そして以下を入力します。
% wine64 GRCsetup.exe
ここが秀丸の記事と違う部分ですが、以下のようなエラーが出ました。
preloader: Warning: failed to reserve range 0000000000010000-0000000000110000 preloader: Warning: failed to reserve range 0000000000010000-0000000000110000 preloader: Warning: failed to reserve range 0000000000010000-0000000000110000 preloader: Warning: failed to reserve range 0000000000010000-0000000000110000 preloader: Warning: failed to reserve range 0000000000010000-0000000000110000 preloader: Warning: failed to reserve range 0000000000010000-0000000000110000 preloader: Warning: failed to reserve range 0000000000010000-0000000000110000 0024:fixme:module:dlopen_32on64_opengl32 loaded "/Applications/Wine Crossover.app/Contents/Resources/wine/lib/wine/x86_32on64-unix/opengl32.dll.so" early @ 0x6a151000 0024: thread_get_state failed on Apple Silicon - faking zero debug registers 0024:err:module:import_dll Library MFC42.DLL (which is needed by L"Z:\\Users\\araky\\Downloads\\GRCsetup.exe") not found 0024:err:module:LdrInitializeThunk Importing dlls for L"Z:\\Users\\araky\\Downloads\\GRCsetup.exe" failed, status c0000135
10行目によるとMFC42.DLLというライブラリーが足りていないようです。ネットで調べた結果、以下を見つけました。
これに従い、以下のようにWineの設定を変更できるwinetricksというものをインストールしました。
% brew install winetricks
そして、これを使って不足していたMFC42.DLLをインストールします。
% winetricks mfc42
この途中で以下のようなプロンプトが立ち上がって来ました。
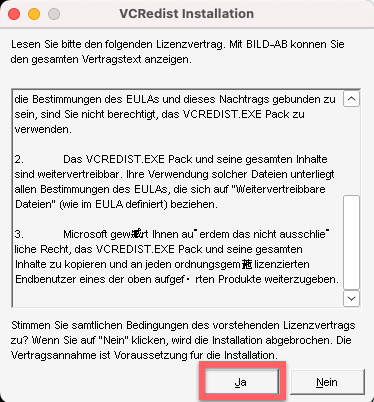
ドイツ語ですが、Yesに相当する「Ja」をクリックします。
そしてもう一度以下を実行します。
% wine64 GRCsetup.exe
すると以下のようなアラートが出ることがありますが、基本的には全部OKで進めます。私のMacは言語を英語に設定してしまっているのでの英語になっていますが、日本語にしている場合は日本語で表示されます。
すると、Windowsで普通にインストールする時のようなセットアップ画面が表示されます。ちなみに、Macの言語を英語にしていると、文字化けしてしまいます。なので、私はこのタイミングでMacの言語を日本語にしました。
Macの言語を英語にして文字化けさせない方法としては、以下でOKでした。
記憶が曖昧なのですが、もしかしたらフォントの導入は不要で環境変数の指定だけで大丈夫かもしれません。
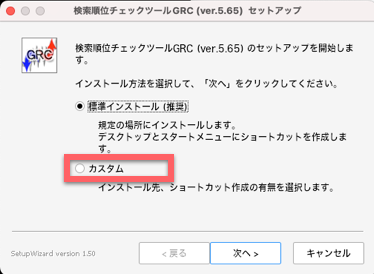
標準インストールでもいいですし、カスタムにしてインストール先などを変えてもいいです。ショートカットなど作る必要はないので、カスタムで進めてみました。
以下のように、デフォルトだと
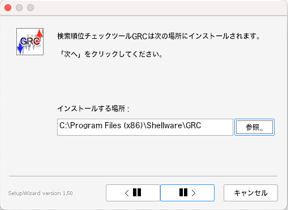
C:\Program Files (x86)\Shellware\GRC
にインストールしようとします。
これは、Macで言うと以下に相当します。(「xxxx」はご自身のホームディレクトリ名に置き換えてください)
/Users/xxxx/.wine/drive_c/Program Files (x86)/Shellware/GRC
つまり、Wineが自動的にMacのホームディレクトリ配下に.wineというディレクトリを作って、仮想的にWindowsのディレクトリ構成を作ります。ちなみに、「.wine」という文字列は変数で変えることもできるので、複数の環境を運用することも可能です。
そして、「参照」ボタンを押すと、インストール場所を選べますが、なんと.wine配下ではない場所も選ぶことができます。以下のようにZドライブがMacの最上位にリンクされているからです。
インストールが完了したらコマンドラインから以下でGRCを起動できます。引数には先程インストールした場所にあるGRC.exeをフルパスで指定します。
% wine64 /Users/xxxx/.wine/drive_c/Program\ Files\ \(x86\)/Shellware/GRC/GRC.exe
すると見事にGRCが起動できます。
起動するまでにかかる時間が本当に普通のMacアプリと同じくらいです。Parallelsの場合は、Parallelsを起動⇒Windowsの起動⇒GRCの起動と手間と時間がかなりかかっていたことに気がつきました。
読みにくい字を綺麗にする
よく見ると、メニューの文字が小さいしギザギザしていて読みづらいです。
左下のステータスバーに表示される文字も同じ感じです。

これは設定で見易くすることができます。winecfgというものでフォント周りの設定を変更することで対処することができます。以下を参考にしました。
wine+DominoやJtrimのサブメニューの文字化け解消
% winecfg
をすると、以下のような設定画面が開きます。
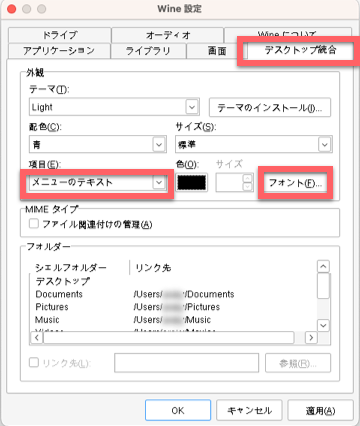
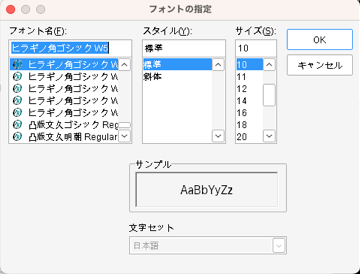
「デスクトップ統合」から「項目」で「メニューのテキスト」を選び、「フォント」をクリックします。これはGRCのメニューのフォントを変える手順です。
次に見やすいフォントを選びますが、私の場合はMacの標準的なフォントであるヒラギノ角ゴシックにしました。なので、「フォント名」は「ヒラギノ角ゴシック W5」、「スタイル」は「標準」、「サイズ」は「10」にしました。
ステータスバーの文字については、「項目」で「ヒントのテキスト」を選択して同じようにフォントを設定します。GRCを再起動すると設定が反映されます。

ただ、ステータスバーはなぜか9という文字の大きさだけ小さくなってしまいます。
スポンサーリンク
普通のMacアプリと同じように起動できるようにする
無事GRCを起動できたものの、毎回いちいちコマンドラインから起動するのが面倒です。なので、以下の記事を参考にGRCを起動するだけのMacアプリを作ります。
記事と違う部分は入力するスクリプトとシェルにはzshを選ぶこととアイコンの画像だけです。アプリの名前は何でも良いですが「GRC」にしておくと綺麗です。
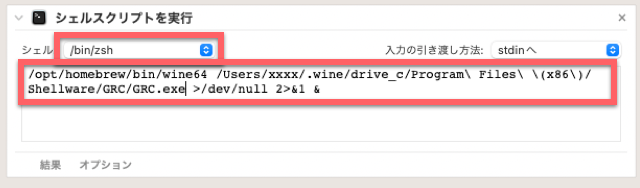
スクリプトは以下。
/opt/homebrew/bin/wine64 /Users/xxxx/.wine/drive_c/Program\ Files\ \(x86\)/Shellware/GRC/GRC.exe >/dev/null 2>&1 &
これで以下のように普通のMacアプリと同じようにアイコンができます。これをクリックするだけでGRCが起動でき、もちろん、Dockにも配置できます。
ところで、先程のスクリプトはコマンドラインで入力したコマンドと違います。このスクリプトのポイントを説明しておきます。wine64をフルパスで指定することと、GRC.exeのパスはあなたの環境に合わせて変えることです。
そして、
>/dev/null 2>&1 & の部分は、以下を参考に処理がバックグラウンドで走るようにしたものです。
Automator gets stuck at shell script
これが無くても動きますが、無い場合、Automatorが処理が実行中だと認識してしまい、Macのメニューバーの右側にGRCを起動している間ずっと「0%完了」と表示されてしまい、気持ち悪いです。
アイコンの画像を設定しなくてももちろん使えますが、そうするとAutomatorと同じアイコンということになります。
わかりやすくしたいので私はGRCのアイコンの画像を取得して設定しました。どのようにGRCのアイコンの画像を取得するかというと、次のツールを使いました。
これもWindowsアプリなのでWineで実行します。zipファイルをダウンロードして解凍するとexeファイルが出てくるので、以下で起動できます。
% wine64 IconExplorer.exe
なぜか画面が緑色なのですが、一応使えます。インストールしたGRC.exeを選び、表示されるGRC_0をクリックします。
右側に表示される一番大きいアイコンを右クリックして表示される「Save toPNG」をクリックします。
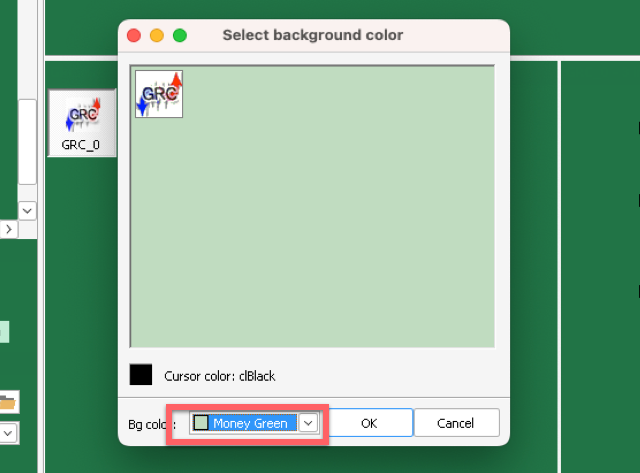
次に表示される背景色を決める画面で、なぜか透明やWhite以外を選択しないときちんとしたアイコンの画像が出力できません。なので、私は適当に以下のようなMoney Greenを選美ました。透明やWhiteを選んでしまうと、なぜかアイコンの画像が透過したものになってしまうのです。
適当な場所にアイコン画像を保存し、先程の記事の手順でAutomatorで作ったアプリのアイコンに適用すると、こんな感じでGRCのアイコンになります。
ドックに配置した場合は以下のような感じです。

ほとんど通常のMacアプリと同じ感覚になりますが、一つ違和感があるのが、起動した後、以下ようにDockにもう一つGRCのアイコンが出現することです。しかも、カーソルを近づけて表示されるアプリ名が「wine64-preloader」となります。
通常のDockにあるMacアプリは起動しているときは、そのアイコンの下に「・」が表示されるだけのはずです。まぁ、これは些細なことなので、対処するのは諦めました。
チェックも正常にでき、有料ライセンスも正常に使えた!
いくつか適当に検索ワードと対象サイトを登録してチェックしてみたところ、正常に確認できました。また、有料のライセンスを購入して、認証もできました。さらに、以前のParallelsで運用していたGRCから持ってきた大量のデータをインポートして、大量のキーワードをチェックしたところ、全て正常にチェックできました。
スポンサーリンク
Parallelsに比べて圧倒的にマシンリソースを節約できる!
Wineは一説にはWine Is Not an Emulatorの略だと言われています。Parallelsのようにエミュレーションを行っているわけではないのでパフォーマンスのロスが少ないとされます。簡単に言えばWineは、Mac上でWindowsを動作させているのではなく、MacにWindowsと同じ挙動をさせているのでです。
なので、速度的にもParallelsより速いです。ただ、GRCで時間がかかる順位チェック処理が短くなると言うことはなさそうです。というのは、この時間は、検索エンジンからのレスポンスを待つ時間や、意図的に何もしない時間が中心だからです。なので、速さは画面上のもっさり感の無さ、キビキビ感に差が出ます。
そして、マシンリソースへの負荷はどのくらい違うのかも気になったので調べてみました。
同じ筐体ではないしMac OSのバージョンも違うので正確な比較ではないかもしれないですが、ざっくりした比較は可能と思われます。古いMacbook ProにあるParallelsでGRCを起動した状態で、アクティビティモニターで表示されるCPUとメモリーの使用状況を調べました。
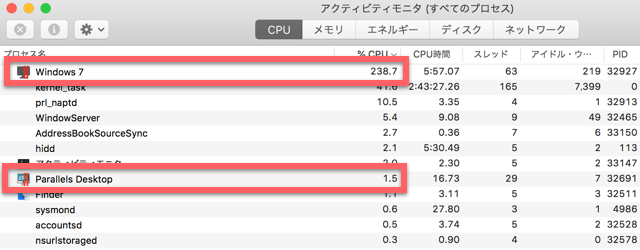
わー、なんとParallels関連のプロセスのCPU使用率を合計すると、240.2%になっていました。100%超えてるのってどういうこと?って思いましたが、CPUのコアが複数あるマシンなので一つ以上のコアを使っている場合は、100%を超えることもあるとのことです。
ちなみに、「Windows7」とありますが、実際はWindows10が走っています。仮想マシンの名前をアップグレード時に変え忘れたままだったので。
あと、Windowsの画面を前面に出していない時は、しばらくするとCPU使用率は5%程度に激減します。おそらくスリープしているのだと思われますが、結局Windows側を触るとすぐに100%を越えてしまいます。
次に、今回導入したWineのCPU使用状況を見てみます。
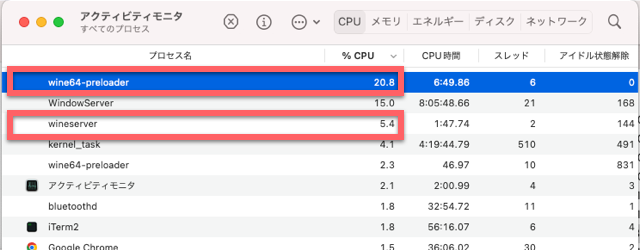
wine64-preloaderとwineserverというプロセスが対象のプロセスになりますが、合計すると26.2%となります。これはGRCを操作している時も、そうでない時も大きな変動はありません。
これだけ違うと電力消費量も大きく違うと思われます。Parallelsを使っていた時、筐体が熱くなってファンがブンブン回っていたのを思い出しました。
次にメモリの使用状況を見ていきます。まずはParallelsの方。
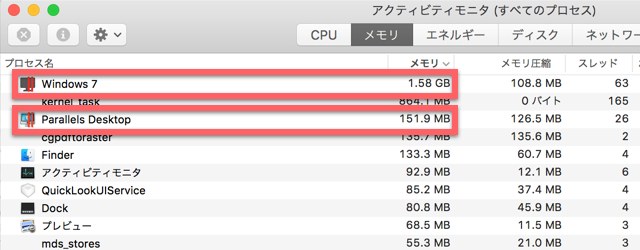
合計すると1.75GB程度とすごい大きさです。しかも、Windowsが前面にない時も、特に減るわけではありません。
次にWineの方を見ます。
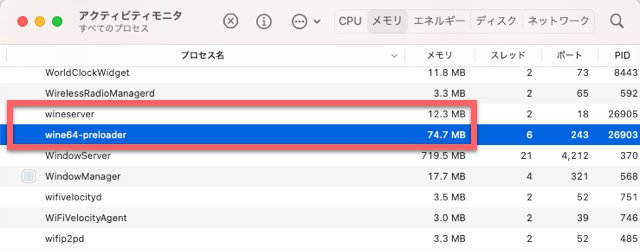
こちらはたったの87MB。これは圧倒的な差です。
明らかに、Wineの方がマシンリソースの使用効率が高いことがわかります。Parallelsの時によくあったメモリ不足に陥ってパソコンが遅くなる機会も減らせそうです。
マシン上のディスク容量がどのくらい使われるかも比べておきます。Parallelsではpvmファイルというのがデータとなります。私の「Windows 7.pvm」はなんと41.08GBもありました。GRCしか使っていないのに。
Wineでは基本的に.wineディレクトリ配下にデータが入ります。.wineはわずか386.2MBでした。これを見ても圧倒的に効率が良いです。
| Wine | Parallels | |
|---|---|---|
| CPU使用率 | 26.2% | 240.2% |
| メモリ使用量 | 87MB | 1.75GB |
| ディスク使用量 | 386.2MB | 41.08GB |
Wine側のバージョンは前述しましたが、一応、Parallels側の環境のバージョンも記載しておきます。
| 端末 | MacBook Pro(2017) |
|---|---|
| Mac OS | 10.13.6 |
| Parallels Desktop | 11 |
| Windows | Windows10 |
| GRC | 5.62.274.1 |
プロセスが残ってしまって起動できなくなる?
全く不満無く使えそうでしたが、不可解なことがありました。
アクティビティモニタでCPUのプロセスを見ると、wine64-preloaderがたくさん立ち上がっているのです。
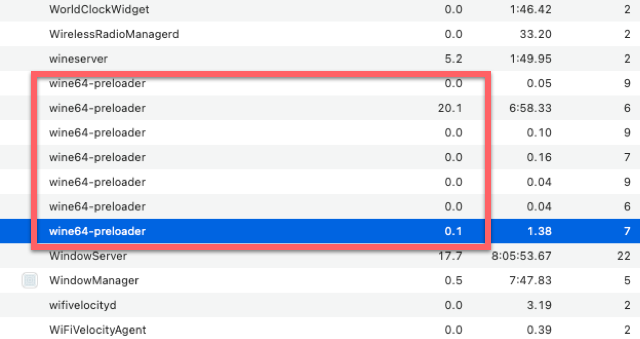
GRCしか起動していないので一つでいいはずです。使用率が0なものがほとんどです。おそらく、20.1のものしか実際には使われてはいないのでしょう。しかし、不思議なことにメモリタブの方を見ると、全てある程度の数字が入っていました。20.1のもの以外全て強制終了してみたところ、問題なくGRCは動き続けました。
さらに不可解なことが起きました。前述したwinecfgでフォントを変えてGRCに反映させるのを繰り返し行なっていた時でした。急にGRCが起動しなくなりました。winecfgも起動しなくなりました。アクティビティモニタを見ると、数え切れないほどのwine64-preloaderが立ち上がっていました。
やはり、winecfgやGRCなどのWindowsアプリを起動するたびに、wine64-preloaderというプロセスが起動するということです。アプリを停止した段階でプロセスも消えるはずですが、なぜか消えなくて大量のプロセスが残ってしまうということのようです。
とりあえず、wine64-preloaderを全て強制終了していきます。しかし、数百個はありそうで、まとめてできずに、少しずつ選択して終了していくのでかなり時間がかかりました。
全部終了できたので、再びGRCを起動しようとしました。しかし、起動しません。winecfgも起動しません。不思議です。色々調査したが原因はわかりませんでした。.wine配下に何かゴミが残ってしまっているのでしょうか。Windowsでいうレジストリ周りにゴミが入ってしまっているのでしょうか。
とりあえず、.wineディレクトリをリネームして、新たに.wineを作成したらGRCが起動できました。(普通にwine64で初めてWindowsアプリを起動する時に.wineディレクトリが作成される)
原因追究のため、リネームした.wineと新しい.wineのdiffをとって比べようとしましたが、複雑にシムリンクされているのでうまくdiffの結果が出ませんでした。なので、とりあえず原因追及は次に起きた時にします。とりえず.wineを新規作成すれば動くようになるとわかったのでそれで満足です。ただ、古い.wineを削除する場合は、GRCのデータを失わないように退避しておくのを忘れないようにしましょう。
以下の記事によるとMac再起動でも動くようになるかもとあるので、次は試してみようと思います。
A bunch of wine-preloader processes are throttling my CPU when running Steam
Parallelsの場合は利用者も多いのでネット上に情報が多く、謎が残ることは少なかったですが、Wineの場合は少しマニアックで、情報もそんなに多くないし、色んなバージョンがあり、定石的な使い方も確立していないように思えます。不安な方は、Wineを使った有償でサポートがある以下の製品があります。とはいえ英語の製品なので、英語がある程度できないとサポートを受けるのも難しいかもしれませんが。
スポンサーリンク
カーソルがGRCから出られなくなる
しばらく使っているとカーソルがGRCのアプリの外に出られなくなる事象が発生しました。しかたがないので、左上の赤ボタンをクリックして終了したら出られるようになりました。再びGRCを起動するとそのような事象は起きませんでした。
また、しばらく使っているとまたカーソルがGRCから出られなくなりました。これが起きるたびに赤ボタンでアプリを停止するのも気持ち悪いし、処理が走っている場合は中断してしまうので、今度は左上の黄色ボタンをクリックしてみました。これを押すと、停止するわけではなくDockに小さく収まります。これでカーソルは自由に外に動けるようになりました。ドック内に入ったGRCをクリックするとカーソルも自由に動ける状態で再び開くことができました。
時々このカーソルの事象が起きるのがちょっと気になりますが、致命的な問題ではないのでまだ調査はしていません。
チェック処理中にMacがスリープしたらエラー
GRCのチェック処理は長い時間がかかりがちです。WineでGRCの処理を流している時に、Macがスリープしてしまいました。スリープから復帰したら以下のエラーが出ました。
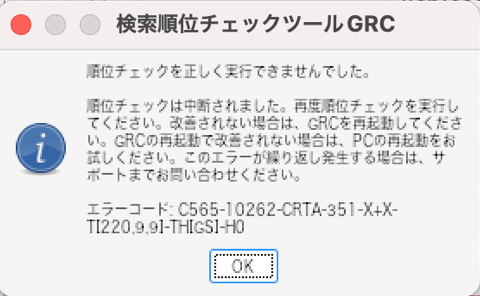
これが出ると、GRCを再起動しないと、再び処理を開始できませんでした。スリープすると100%起こるわけではないが、時々こういうことがあります。なので、GRCのチェック処理を流すときはスリープしないようにMacの設定をする必要があります。Macbook A
irは、持ち歩くノートパソコンなので基本的にはスリープする設定にしておきたいので悩ましいところです。
Parallelsの時は、Macがスリープしてもスリープ解除したら知らぬ間に処理をよしなに再開してくれていました。先ほどのカーソルのような事象も起きません。さすがParallelsは有料ソフトだけあって、この辺りのユーザビリティは考えられています。
スポンサーリンク
Macアプリからのコピー&ペーストができない?
Evernoteというノートアプリで検索キーワードをまとめていて、それをまとめてコピー&ペーストでGRCに持ってきてペーストしようとしたらできません。何も文字が出てきません。GRC内でのコピー&ペーストは機能しています。
試しにGRCを再起動したら、Evernoteからのコピー&ペーストができるようになっていました。何だったのでしょうか。やはり少し不安定です。とはいえ、そんなに致命的な問題ではないので我慢します。おかしな事象が起きたらとりあえずGRCの再起動で対処します。
共有ドライブに.wineを配置したら複数端末から使える?
まだやっていないのだが、.wineディレクトリをDropboxなどのリモートディスクに配置して、使う時は端末にマウントして動かせば、もしかしたら複数端末から利用できるかもしれません。GRCのライセンス認証がどのような仕組みで行われているかりませんが、認証データが.wine内に配置され、物理的に端末に紐づかないなら可能でしょう。
ちなみに、こちらもやっていないませんが、Parallelsで運用する場合でも、理論上はpvmファイルをリモートディスクに配置して複数端末から使えるはずです。ただ、pvmファイルは前述したように数十GBもあるので、毎回ネットワークを介して端末に転送するのは現実的ではありません。
それに対して、.wineディレクトリをマウントするだけなら、せいぜい400MB程度なので可能でしょう。とはいえ、GRCの規約的にこのような使い方をして良いのかは精査していません。リモート上のWindowsに1ライセンス分のGRCを入れて複数端末から使うという使い方は普通にされているようなので、それと同じようなものな気はします。やってみる場合は、ご自身で規約を確認して自己責任でしてください。
.wineディレクトリを端末間で共有できたら、Macを2台持っている人なら、家にあるMacは常時起動し毎日決まった時間にGRCを走らせる設定にしておいて、出先ではノート型のMacでGRCのデータを確認だけする、といった使い方も可能かもしれません。こうすれば、持ち歩くMacのスリープの設定に悩むことはありません。ただ、複数端末から同時にマウントして起動した場合、ファイルが壊れたりしないかといった心配はありますが。
スポンサーリンク
まとめ
Macで検索順位をチェックする手段としてのWine+GRCの良い点、悪い点をまとめておきます。比較対象としては、私がこれまで使ったことのあるParallels+Windows+GRCやSERPOSCOPEとなります。
- WindowsやParallelsのライセンス料がかからない
- 起動する手間と時間がかからない(Macアプリと同レベル)
- エミュレーターではないので処理が速い
- マシンリソースの使用効率が圧倒的に良い
- コマンドラインからの設定が必要で少しハードルが高い
- ネットの情報が比較的少なく、自力で解決しなければならない状況が多い
- スリープ復帰時に落ちる等、少し不安定なところがある
正直、ITに疎い方にはハードルが高いのでこの方法はおすすめしません。でも、現在初心者であっても、ITに関心があって学習意欲がある方は挑戦する価値があると思う。ここで得た知見は、パソコンを少しでも使う仕事をしているなら使えるし、サイト運営でも間違いなく役に立ってくるので。
The post Macの検索順位チェックツールはWine+GRCが効率とコスパ抜群! first appeared on WebFood.
]]>The post "嫌われる勇気"の要約と感想!大量の矛盾点との向き合い方 first appeared on WebFood.
]]>何度も読んでいる「嫌われる勇気」の要約と感想です。最近人付き合いで困ったことがあり、ヒントが得られればと思い、しっかり理解するために記事にします。
要約
青年と哲学者(哲人)の2人の会話形式で進んでいく。そのため、読みやすく、さくさく読み進められるが、構造的な記述になっていないし、各概念のつながりが明示されていないことも多いので、わかったようでよくわかっていない、という状態になりやすい。なので、この要約では、各概念の構造的な関係を意識して記述していきたい。概念間の明示されていないつながりは、吹き出し部分で私の推測として記述する。引用箇所に示したNoはKindle版での位置Noのこと。

原因論ではなく目的論
ある青年が、「人は変われる、世界はシンプルである、誰もが幸福になれる」と提唱している哲人に議論を挑むところから始まる。
人は変われないと思っている人は、目的論ではなく原因論に立脚している。例えば、引きこもりの人は「外に出ない」という目的があって、その目的を達成する手段として不安や恐怖といった感情をこしらえいてる。また、その目的を達成する手段としてトラウマなどの過去の経験を持ち出す。
人は変われる
「大切なのはなにが与えられているかではなく、あたえられたものをどう使うかである」とアドラーは言う。なので「所有の心理学」ではなく、「使用の心理学」と呼ばれる。
アドラー心理学では、性格や気質を「ライフスタイル」というが、人は自らのライフスタイルを自分で選んでいて、変われないと思っている人は自分のライフスタイルを変えないでおこうという決断を常にしているということ。
なぜ所有の心理学だと人は変われなくて、使用の心理学だと人は変われるのか。前者は与えられたものが全て。自分に何の選択の余地がない。選択できないのだから、一度与えられたら変わりようもない。
例えば、あなたはある軍隊の一人の兵隊だとする。しかし、その軍隊は武器不足で武器が寄せ集めしかなく、統一していない。ある者は機関銃、ある者は拳銃、ある者は刀が与えられたが、あなたはなんと短いナイフだけ。
この時点で「所有の心理学」で考える人だと、「もうダメだ。ナイフ一本でこの戦争で活躍できるはずがない。」という発想になる。しかし、「使用の心理学」で考える人だと、「ナイフは夜襲の接近戦だと一番使えるぞ。」だったり、「ナイフで調理することで他の兵隊の食事を作ってあげられる。」と考えられる。なので、人は変わることができる。全く活躍できないと思っていたが、実は十分に活躍できる、ということになる。
「選択の余地」という表現をしたが、最初「工夫の余地」もあるかな、と思った。でも、ここは「自分で選ぶ」ということに一番焦点を当てるべきなので、「工夫の余地」は言及しなくてもいいかな、と思う。もちろん、「工夫の余地」はあるのだが、工夫は頭を使うことだ。でも、ここで言いたいのは頭を使わなくたって、頭が悪くたって、自分で選べるんだっていうことだと思う。
ちなみに、与えられたものをどう使うかという「使用の心理学」が、「ライフスタイル」を選ぶということとどうつながるのかよくわからない。与えられたものの使い方を選ぶ、ということがライフスタイルを選ぶということなのかな?
その人が何を持っているかはどうあれ、性格や気質というものは自由に決められるってことか。「使い方」イコール「ライフスタイル(性格や気質)」っていう解釈はできないかな。その方がすっきりできる。
以下のように、ライフスタイルを「世界や自分への意味づけ」としている箇所もあり、これは「使い方」に近い気がする。
世界や自分への意味づけ(ライフスタイル) を変えれば、世界との関わり方、そして行動までもが変わらざるをえなくなります。
(位置No 667)
また、後半に語られる「人生の意味」もほとんどライフスタイルと同列に語られる。
「人生の意味は、あなたが自分自身に与えるものだ」 と。
(No.3568)
ここまで来ると、原因論と目的論で説明される「目的」も自分で選べるということなので、同じ意味と言えると思える。
なので、
「与えられたものの使い方」=「性格や気質」=ライフスタイル=「世界や自分への意味づけ」=「人生の意味」=「目的」
と言えそうだ。
ただ、一般的な性格や気質って、「無意識な反応」を意味することが大きいと思う。例えば、性格を表現する時、「あの人は慎重だ」とか「あの人は大雑把だ」とか。人の性格って、色んな側面があるので、その全てを選びようなくないかな。と思う。自分でも認識できないものも多いし。
与えられたものの使い方って、人生をどう生きるか、など、もう少し大まかな方向性しか関わっていなくて、性格はもっと詳細なものだから、選べるのかは疑問。なので、ライフスタイルを「性格や気質」って言ってしまうのは疑問。
可能性のなかに生きる
「もしも何々だったら」と可能性のなかに生きているうちは、変わることはできない。変わらない自分への言い訳としてそういうことを言う。
「もしも赤面症が治ったらわたしだって」「合格すれば人生がバラ色になる」「転職すればすべてうまくいく」というのは、全て今ライフスタイルを変えないための言い訳である。
「こんな短所だらけの自分でなければ」というのは、対人関係で傷つかないように、最初から誰とも関わりを持たないための言い訳。
これらの例を見ればわかるように、アドラーは「人間の悩みは、すべて対人関係の悩みである」と主張する。
「合格すれば」や「転職すれば」の合格や転職は、与えらたものというより、自分で得るもののように思えるので、赤面症や短所だらけの自分とは違うのかな、と感じた。でも、努力でそのうち持てるものでも、「今」持っていないものは「与えられていない」と考えるのがアドラー心理学ということか。
対人関係から生まれる劣等感
私たちの悩みは劣等感から生じる。つまり他者との比較(対人関係)から生まれる。ただ、その劣等感もあくまで主観的なもの。例えば、平均に比べて身長が低いという劣等感がある場合、低身長が人を安心させると効果があるととらえれば長所となり、劣等感はなくなる。
劣等感はドイツ語だと「価値」が「より少ない」「感覚」という意味。
そもそも「価値」とは、単なる紙に印刷された紙幣を例にとればわかるように、社会的な文脈の上で成立しているもの。
前パートからのつながりを考えると、「悩み」=「劣等感」ということだろう。劣等感のもととなる「価値」に関して、ここでは二段階の不確定性の存在があると言っていると感じた。
まず、一段階目は、価値は絶対(※)的なものではなく、社会的な文脈の上で成立する、という点。(※本文では「客観」と言う言葉を使っているが「絶対」の方が言葉として合っていると思う。「客観」というのは自分以外の複数の視点があれば成立するはずなので「社会的な文脈」というのは十分「客観」と呼べるから。)
そして、二段階目は、社会的な文脈で「価値」が成立しても、主観的な解釈しだいで動かすことができる。
つまり、価値とは全く確定していないふわっとしているもの、ということ。
世の中の全員がこれを完全に理解していれば悩み(劣等感)で苦しむ人はいない。でも、多くの人が苦しんでいるというのは、おそらく二段階目を理解していないからではないかと思う。一段階目は普通に生きていてもある程度賢ければ理解できる。価値っていうのは絶対的ではなくて社会が決めているんだなー、時代や国によっても変わるしなー、くらいには思える。でも、二段階目はどこかでアドラー的な考えを学んでいないと理解していない人が多いと思う。
前パートの「可能性のなかに生きる」と劣等感がどうつながるかがわかりづらい。価値というのが自分ではコントロールできないと思っている人は、「絶対的な価値」に直面せざるを得なくなり、多くの劣等感にさいなまれるのを怖れて、対人関係に踏み出さない。そのような人を「可能性のなかに生きる」と言っているのかもしれない。
優越性の追求と劣等コンプレックス
劣等感は誰もが持っているし、あったとしても悪いものではないが、いつまでもその状態を我慢することはできないほど重いもの。それを取り除くために向上しようとすることを「優越性の追求」という。これは健康で正常な努力と成長への刺激である。
しかし、自らの劣等感をある種の言い訳に使いはじめた状態のことを「劣等コンプレックス」という。「わたしは器量が悪いから、結婚できない」というように「Aであるから、Bできないという論理」を振りかざした場合、劣等感を超えて劣等コンプレックスと言える。この論理を「見かけの因果律」という。本来はなんの因果関係もないところに、あたかも重大な因果関係があるように自らを説明し、納得させてしまう、ということ。
「Aであるから、Bできないという論理」を言葉や態度に出す人は「Aさえなければ、わたしは有能であり価値があるのだ」と暗示することになり、優越コンプレックスになる。ブランド品や権威を過剰にアピールしたり、実績を自慢したり、不幸を自慢するのも優越コンプレックスになる。
劣等感を健全な努力と成長で補償しようという勇気が持てない人が、劣等コンプレックスや優越コンプレックスに踏み込んでしまうという意味で、両コンプレックスは地続きである。
日本で一般的に使われる「学歴コンプレックス」などコンプレックスは劣等感の意味で使われているが、これは誤用。
優越性の追求というと、他者を蹴落としてまで上に昇ろうというように聞こえるが、そうではなく、同じ平らな地点でそれぞれの道を一歩前に進む意思である。誰とも比較する必要はなく、理想の自分と比較して一歩前に行くことだ。
劣等感は対人関係のなかで生まれ、哲人も他者と身長を比べることで劣等感を感じたと言っているのに、以下のように言っているのがよくわからない。
健全な劣等感とは、他者との比較のなかで生まれるのではなく、「理想の自分」との比較から生まれるものです。
(位置No.1118)
劣等感にも2段階あるってことかな?健全な劣等感と不健全な劣等感というように。最初は他人との比較から不健全な劣等感から入って、優越性の追求をする段階だと、「理想の自分」との比較と捉えて前に進んでいくということか。
劣等感の解消方法として、哲人は低身長について主観的な解釈を変えるという方法をとった。優越性の追求をしたわけではない。なので、劣等感の解消方法も2段階あると考えたほうがいいかも。
最初に他者との比較で不健全な劣等感を感じる。その内容が、
- 身長のようなどうにもならないもの⇒主観的な解釈を変える
- どうにかなるようなもの⇒「理想の自分」との比較ととらえて健全な劣等感に変えて優越性の追求に踏み出す
ということなのかなと理解した。
ただ、どうにかなるのかどうか、どうにもならないのか、の判別はどうするのか?身長だって、昨今では一度脚の骨を折って伸ばすという手術である程度伸ばせるという医療技術があるようだ。それはやりすぎととらえるか健全な努力ととらえるかは難しい。
それは以下のニーバーの祈りにある知恵が必要になるということか。
神よ、願わくばわたしに、変えることのできない物事を受け入れる落ち着きと、変えることのできる物事を変える勇気と、その違いを常に見分ける知恵とをさずけたまえ
(位置No.2900)
知恵って言われてもよくわからないなー、と思ったけど、要は自分から見て滑稽かどうかかな、と思う。身長を伸ばすために、四六時中祈ったり、変な業者に高額な依頼をしたり、滑稽なほどの努力をしているのは、もうそれは変えることができないもの、と捉えるべきってことかもしれない。
人生は他者との競争ではない
理想の自分との比較ではなく、他者と比較してしまうと、対人関係の軸に「競争」があることになる。そうなると、人は対人関係の悩みから逃れられず、不幸から逃れることができない。他者全般のことを、ひいては世界のことを「敵」だと見なすようになる。
逆に競争を軸に考えなかった場合は、人々は「仲間」と捉えられるようになり、他者の幸福を「わたしの負け」と捉えず、心から祝福できるようになる。
他者に面罵されたり、相手の言動によって本気で腹が立った時は相手が「権力争い」を挑んできている。その場合、いかなる挑発に乗ってはいけない。「怒りという道具」に頼らず、怒り以外の有用なコミュニケーションツール、言葉の力を信じて使う。
自分の方が正しいと確信した瞬間、すでに権力争いに足を踏み入れている。正しいと思うのなら他の人がどんな意見であれ、そこで完結するべき。しかし、多くの人は権力争いに突入してしまう。
自分が正しいと思っても、権力争いから降りる、というのはわかるのだけど、誤りを認めたり、謝罪の言葉を述べることをすすめているように読める。正しいと思っているのに自分が誤っていたというのは逆に不誠実ではないか。
自分が正しさを主張したい時、それが誠実さからくるのか、権力争いからくるのかを見極める必要があるということか。
対人関係は避けられない
他者を敵だと見なさず、仲間だと思うためには、「幸せになる勇気」を持って「人生のタスク」に逃げずに向き合うこと。
人はひとりでいきていくことなど原理的なありえない。なので対人関係が重要になる。そのために、
行動面の目標が
- 自立すること
- 社会と調和して暮らせること
行動を支える心理面の目標が
- わたしには能力がある、という意識
- 人々はわたしの仲間である、という意識
これらの目標は以下3つの「人生のタスク」と向き合うことで達成できる。
- 仕事のタスク
- 交友のタスク
- 愛のタスク
人は人生のタスクを回避するために、他者の欠点を探し「敵」と思うことで対人関係から逃げる。これを「人生の嘘」という。誰かを嫌っている場合、その人を嫌うという目的が先にあって、その目的にかなった欠点をあとから見つけ出している。
対人関係を重視する理由の説明がちょっと少ない。「避けられない」くらいしか書いていない。金が有り余っていて、人と合わなくても暮らせるケースもなくはないじゃないか。
あと、3つの人生のタスクの説明において、対人関係の距離と深さを強調しているが、これがなんのことかよくわからない。3つの違いは、距離と深さの違いということか?
距離が遠くて、深さが浅い順に
- 仕事のタスク
- 交友のタスク
- 愛のタスク
ということか。
そして、以下のように書いているので、「対人関係」=「人生のタスク」といってもいいのかもしれない。
ひとりの個人が、社会的な存在として生きていこうとするとき、直面せざるをえない対人関係。それが人生のタスクです。 この「直面せざるをえない」という意味において、まさしく「タスク」なのです。
(位置No.1387)
人生のタスクの必要性として、他者を敵ではなく仲間とみなすため、というのと、社会的な存在として生きて行くには直面せざるを得ない、という、2点出てきているが、どちらなのか?他者を敵とみなしてしまうと社会的な存在として生きていけない、ということか?でも青年はまがりなりにもこれまで生きてこれているじゃん。
勇気の心理学であり使用の心理学である
人生の嘘にすがり、人生のタスクを回避するのは、道徳的に糾弾されるべきではなく、勇気の問題である。人間は原因論的なトラウマに翻弄されるほど脆弱な存在ではなく、目的論の立場にたって、自らの人生、ライフスタイルを自分の手で選ぶことができる。その勇気が必要。それが幸せになる勇気。
アドラー心理学は「勇気の心理学」であり、「使用の心理学」である。つまり、「与えられたものの使い方(ライフスタイル)」を選ぶことができる、という勇気を持とう、ということ。
スポンサーリンク
課題の分離をして自由を得る
その勇気を得るためには自由が必要になる。その具体的な方法として「課題の分離」がある。自分の課題と他者の課題を分離するということだ。誰の課題か見分けるには、「その選択によってもたらされる結末を最終的に引き受けるのは誰か?」を考える。
したがって、承認欲求は否定される。その選択について他者がどのような評価を下すのか。これは他者の課題であって、自分にはどうにもできない話だから。
しかし、他者に嫌われたくないと思うことは、自然な欲望であり衝動で、近代哲学の巨人、カントはこうした欲望を「傾向性」と呼んだ。本当の自由とは、このような欲望のおもむくままに、坂道を転がる石のように生きるのではなく、転がる自分を下から押し上げていくような態度である。
自然な欲望なのに、それを否定するのが当然かのように説明している哲人は意地悪だなと思った。
アドラーは自然な欲望を認めない、ということなのか。自然な欲望を肯定する考え方が溢れている現代では異質だ。
自然な欲望といえば、食欲、睡眠欲、性欲などがある。食欲や睡眠欲は満たされて当然であり、満たされないと死んでしまう。性欲は満たされなくても死にはしない。なので、承認欲求は性欲に近いと思った。
性欲は満たされることもあるが、満たされないこともある。相手がある話だからだ。承認欲求も同じで、満たされることもあれば、満たされないこともあるということか。性欲や承認欲求を、食欲や睡眠欲と同じように、満たされて当然と思っていると色々問題が発生する。満たされなくてもいいやー、くらいに思っていなければならない。
ただ、哲人は承認欲求を認めないどころか否定までしている。もし承認されたとしても喜ばないほうがいいということだと思う。性欲の場合、もし性欲を満たす機会があった時に、喜ばないほうがいいということになるのかな。それはちょっと不自然すぎる気もする。なので私のこの喩えは無理があるか。しかし、性欲も否定してしまったほうがアドラー的な自由には近づく気もする。
嫌われる可能性があっても課題を分離することで対人関係から自由になれる。なので、「自由とは、他者から嫌われることである」と哲人は言う。誰かに嫌われているということは、自由に生きている証だ。他者の評価を気にかけず、他者から嫌われることを怖れず、承認されないかもしれないというコストを支払わないかぎり、自分の生き方を貫くことはできない。これが本をタイトルにもなっている「嫌われる勇気」。「幸せになる勇気」には「嫌われる勇気」も含まれる。
哲人はアレクサンドロス大王のゴルディオスの結び目の逸話を課題の分離になぞらえる。
このとき彼は、「運命とは、伝説によってもたらされるものではなく、自らの剣によって切り 拓くものである」と語ったといいます。
(中略)
このように、複雑に絡みあった結び目、つまり対人関係における「しがらみ」は、もはや従来的な方法で解きほぐすのではなく、なにかまったく新しい手段で断ち切らなければなりません。
(位置No.1908)
なぞらえるだけで、結局どういう意味なのか説明しないのが哲人の不親切なところだなぁと思いましたが、ここから私は課題の分離をする時の心得を考えた。2通りの解釈ができると思います。一つは、「新しい手段」ということなので、クリエイティブな方法を考える必要があるということ。もう一つは、丁寧に結び目をほどくのではなく、切ってしまうということなので、ある程度強引に断ち切ってしまうということ。
前者だとしたらもう少し説明が必要だと思うので、後者なのかなと思った。つまり、課題の分離はエイヤーっとある意味無理やりやる必要があるってことだと思う。これって無駄に摩擦を生まないかな。他者の期待に関係なく自分の方針で行動するのはわかるけど、わざわざその時に人と軋轢を生む必要があるのかな。ただ、軋轢を生まないためのケアが負担になって自分の方針で動けないくらいなら、そんなケアをする必要ない!ってことなのかな。
課題の分離から出発し共同体感覚がゴール
課題の分離は対人関係の出発点で、「共同体感覚」が対人関係のゴールとなる。共同体感覚とは、他者を仲間だとみなし、そこに「自分の居場所がある」「ここにいてもいいのだ」と感じられること。
課題の分離は「人生のタスク」、つまり対人関係に向きあうための勇気と自由を生み出すためのものという話の流れだったが、ゴールは「共同体感覚」だと説明される。では、人生のタスクと共同体感覚はどのような関係にあるのか。
共同体感覚は共同体に対して自らが積極的にコミットすることで得られる。「人生のタスク」に向き合うことが、すなわち積極的にコミットすることになる。「この人は私に何を与えてくれるのか?」ではなく、「わたしはこの人になにを与えられるか?」を考えなければならない。それが共同体へのコミット。そのために自分は世界の中心にいるのではなく、共同体の一部であることを認識する必要がある。
不幸の源泉は対人関係にあるが、逆にいうと、幸福の源泉も対人関係にある。共同体感覚とは、幸福なる対人関係のあり方を考える、もっとも重要な指標。
共同体で苦しみを感じることもあるが、われわれが対人関係のなかで困難にぶつかったとき、出口が見えなくなってしまったとき、まず考えるべきは「より大きな共同体の声をきけ」という原則。そうすれば共同体感覚を持ちながらも自由を選べる。
つまり、
課題の分離⇒人生のタスク⇒共同体感覚
の流れで達成されると理解した。
一つ疑問なのは、共同体のなかに自分のことを嫌う人や罵倒してくる人がいた場合、「ここにいてもいいのだ」と思えるだろうか。となると共同体感覚を得るには、やはり他者に好かれなければならないのではないだろうか。
もう一つ疑問なのは、共同体感覚を持つことが幸福な対人関係の指標というが、どのように幸福なのかが詳しく描かれていないこと。「わたしはここにいてもいいいんだ。」と思えることは良いことだと思うが、それが一番重要なことだろうか、と思ってしまう。居場所があることが、どれだけ素晴らしいことなのかをもっと語ってほしい。
序盤では人生のタスクは、避けられない対人関係、という説明だったが、ここからはいきなり「わたしはこの人に何を与えられるか?」を考えること、というように、与えるという概念が入ってくる。飛躍している。もう少し説明が欲しい。
横の関係と勇気づけ
課題の分離でどのように人生のタスクを乗り越え、共同体感覚に至ればいいのか、そのためには「横の関係」必要になる。「同じではないけれど対等」という意識。これによって良好な対人関係につながる。
具体的にはほめてはいけないし、しかってもいけない。これらには評価や操作が背景にあるため。そもそも劣等感とは縦の関係の中から生じてくる意識。
横の関係に基づくアプローチは「勇気づけ」と呼ぶ。人が課題を前に踏みとどまっているのは、その人に能力がないからではない。能力の有無ではなく、純粋に「課題に立ち向かう〝勇気〟がくじかれていること」が問題なのだ、と考えるのがアドラー心理学。
具体的には、「ありがとう」と感謝の言葉を伝えたり、「うれしい」と素直な喜びを伝えたり、「助かったよ」とお礼の言葉を伝える。これが横の関係に基づく勇気づけのアプローチ。
人は自分には価値があると思えたときにだけ勇気を持てる。ではどうすれば価値があると思えるのかというと、共同体、つまり他者に働きかけ、「わたしは誰かの役に立っている」と思えること。他者から「よい」と評価されるのではなく、 自らの主観によって「わたしは他者に貢献できている」と思えること。そこではじめて、われわれは自らの価値を実感することができる。行為のレベルではなく、存在のレベルで見て、それ自体を喜び、感謝の声をかけていくのが大事。
自己への執着を他者への関心に切り替える
共同体感覚を持つのに邪魔となる自己への執着を他者への関心に切り替えるのに必要になるのが、「自己受容」「他者信頼」「他者貢献」。
自己受容と対照的なものとして自己肯定がある。自己肯定とは、できもしないのに「わたしはできる」と自らに暗示をかけること。これは優越コンプレックスにも結びつく発想。一方、自己受容とは、できないのだとしたら、その「できない自分」をありのままに受け入れ、できるようになるべく、前に進んで行くこと。
これは、「肯定的なあきらめ」といえる。課題の分離もそうだが、「変えられるもの」と「変えられないもの」を見極める、「変えられるもの」に注目していく。「あきらめ」という言葉には、元来「明らかに見る」という意味があり、物事の真理をしっかり見定めることで、悲観的なことではない。
他者信頼とは、他者を信じるにあたって一切の条件をつけないこと。担保などの客観的などを必要とする信用とは違う。だまされてしまうこともあるが、自己受容ができていれば、裏切りが他者の課題であることも理解できるので、他者信頼に踏み込む勇気が持てる。ただ、道徳的価値観に基づいて信頼するのではなく、横の関係を築くために信頼する。なので、その人と関係を築きたくないと思えば断ち切ってしまっても構わない。これは自分の課題。
自己受容ができて他者信頼ができる。そうすると、他者を仲間だと思える。そうすると、「ここにいてもいいんだ」という所属感を得ることにつながっていく。ただ、共同体感覚を得るためには「他者貢献」も必要になる。
他者貢献とは、仲間である他者に対して、なんらかの働きかけをしてくこと。ただ、自己犠牲ではない。他者のために自分の人生を犠牲にしてしまう人は「社会に過度に適応した人」。むしろ、他者貢献とは「わたし」の価値を実感するためになされるもの。偽善のように聞こえるが、他者を「敵」だと見なしたままおこなう貢献とは違い、「仲間」だとみなしておこなう貢献は、偽善にはならない。
人生の調和を欠いた生き方
神経症的なライフスタイルを持った人は、なにかと「みんな」「いつも」「すべて」といった言葉を使う。「みんな自分を嫌っている」とか「いつも自分だけが損をする」とか「すべて間違っている」というように。もし、これら一般化の言葉を口癖としているようなら、注意が必要。これを「人生の調和」を欠いた生き方という。
吃音の人、ワーカホリックの人などはこれに当たる。吃音の人は、言葉を詰まらせたことを笑う少数の人だけに注目して「みんなわたしを笑っている」と考えてします。
仕事は会社だけでなく、家庭、地域、趣味など色々な仕事があるのに、会社の仕事だけしか考えない人がワーカホリック。こうした人は、仕事を口実に他の責任を回避していて、これは人生の嘘だ。そして、「行為のレベル」でしか自分の価値を認めることができていない。
自分を「行為のレベル」で受け入れるのか、それとも「存在のレベル」で受け入れるか。これはまさに「幸せになる勇気」に関わってくる問題。
明言はしていないが、この本ではどちらかでいうと「存在のレベル」を重視しているように感じる。だから、「いまこの瞬間から幸福になることができる」という発言が出てくるんだと思う。また、行為のレベルにとらわれていて家庭を顧みない青年の父を批判的に見ているのもそう。
幸福とは貢献感である
他者貢献をすることによって「わたしは誰かの役に立っている」という主観的な感覚が「貢献感」。ほんとうに貢献できたかどうかは原理的にわかりえない。つまり、目に見える貢献ができなくてもいい。
つまり、幸福とは貢献感である。
ただ、承認欲求を通じて得られた貢献感には自由がない。もし本当に貢献感が持てているのなら他者からの承認がなくても「わたしは誰かの役に立っている」と実感できる。
貢献感は主観的に感じられればよく、目に見える貢献でなくてもいい、行為のレベルでなく存在のレベルの貢献でいい、とのことなので、形が何もない。でも、少なくとも、対象の共同体は決める必要がるし、決めることが大事だと思う。というのは、対象を決めなければ主観的な貢献も生まれないから。
普通であることの勇気
貢献感だけが幸福なのか。歴史に名を残したり、自己実現的なことをする高邁な目標を目指すのも幸福なのではないかという疑問が湧く。
われわれは「優越性の追求」という普遍的な欲求を持っていてこれは悪いことではない。しかし、健全な努力を回避したまま、特別な存在になろうとすることは「安直な優越性の追求」と言える。「特別によくあろう」としてなれればいいが、通常それは難しいので「特別に悪くあろう」としてしまう。例えば非行に走る子供。
そもそも「特別」になる必要はない。「普通の自分」を受け入れることは、わざわざ自らの優越性を誇示する必要がないということ。それが「普通であることの勇気」。
安直な優越性の追求って、ちょっとトリッキーなことをして目立とうとするのもそうかもしれない。マリオカートで逆走するとか。
なぜ「普通」を避けようとするのがダメかというと、「普通」という考え方自体が、他者との比較から生まれれるからかな、と思った。他者と比較して普通かどうか、そう考えている時点で、理想の自分とではなく他者と比較してしまっているから。なので、「普通であることの勇気」は意識して普通になれといっているわけではない。普通なんて意識するな、結果的に普通になっちゃったとしてもそれは受け入れろ、ということだと思う。
人生は線ではなく点の連続
高邁なる目標を目指す人生とは、人生を登山のように考えていて、自らの生を「線」としてとらえている。これは原因論に繋がる考えで、人生の大半を「途上」としてしまう考え方。
線ではなく、人生は点の連続であり、今この瞬間をダンスするように生きる連続する刹那。「いまなしつつある」ことが、そのまま「なしてしまった」ことであるような動き、つまり、「過程そのものを、結果とみなすような動き」。
過去や未来を見ることは自らに免罪符を与えることにつながる。「いま、ここ」に強烈なスポットライトをあてていたら、過去も未来もみえなくなる。「いま、ここ」だけを真剣に生きるべき。
原因論に立つ人は、人生を大きな物語としてとらえているが、点としてとらえれば物語は必要なくなる。
このあたり禅やマインドフルネスで言われる「いま、ここ」に近い考え方な気がする。
人生の意味は自分で与える
人生が「いま、ここ」しかないとしたら、人生の意味とは何だろうか?アドラーは「一般的な人生の意味はない」という。しかし、その人生に意味を与えることができる。「他者に貢献するのだ」という「導きの星」さえ見失わなければ、なにをしてもいい。
アドラー的な生き方をするように「わたし」が変われば、「世界」が変わってしまう。世界とは、他の誰かが変えてくれるものではなく、ただ「わたし」によってしかかわりえない。「わたし」の力は計り知れないほど大きい。これは長年禁止だった人がメガネをかけた時の衝撃の似ている。不鮮明だった世界の輪郭が明らかになり、色までも鮮やかになる。他の人が協力的でないとしても、自分が始めるべき。
このあたりで
「人生に与える意味」=ライフスタイル
と思えるような記述がたくさんある。
私の批判的な感想&疑問
スポンサーリンク
目的論は目的の肯定ではなく目的の否定?
「原因論ではなく目的論」というがその目的はどのように決まっているのだろうか?過去に何か出来事があって目的を決めているのではないか?
そして、「目的」という言葉は、アドラーが否定する人生を登山とするような発想の言葉ではないか?ここで言いたいのは、目的なんか持っているからそうなるんだ!ということなのか。目的なんか持つな!と。悪い目的を良い目的に変えようと言っているわけではなく、目的を持つこと自体を否定しているということか。終盤で目標や計画を否定しダンスするように生きろと言っているし。
ただ、赤面症や引き込もりの例にしても、目的を捨てるには目的を認識しなければ難しいのでは?あっ、私、ふられるのが怖いから接触を避る、という目的のために赤面症になっているんだ、と認識できないと、目的捨てられないよね。その目的を認識するために何をすればいいかはこの本には書いていないんだよね。
カウンセラーを舐めすぎでは?
フロイトなどの非アドラー的なカウンセラーや精神科医を批判する記述が多いが、偏っていると思う。
あなたが風邪で高熱を出して医者に 診 てもらったとします。そして医者が「あなたが風邪をひいたのは、昨日薄着をして出かけたからです」と、風邪をひいた理由を教えてくれたとしましょう。さて、あなたはこれで満足できますか?
(No.275)
原因がわからないと、対策も出てこないのではないか?「薄着」という明確な原因がわかれば、これからは薄着をしなければ風邪をひかないということはわかる。原因がわからなければ、二度三度と同じ苦労を味合わなければならないではないか。
ところが原因論に立脚する人々、たとえば一般的なカウンセラーや精神科医は、ただ「あなたが苦しんでいるのは、過去のここに原因がある」と指摘するだけ、また「だからあなたは悪くないのだ」と 慰めるだけで終わってしまいます。
(No.281)
過去の経験から、現状の見方の歪めて見ていることを気づかせるのが現代的なカウンセリングだと思う。「だからあなたは悪くないのだ」で終わることはなく、その歪みにしっかり向かい合いましょうっていうスタンスの方が多いでしょ。
トラウマの意味付けを変えるには過去見つめる必要あるんじゃない?
以下のようにある。
アドラーはトラウマの議論を否定するなかで、こう語っています。「いかなる経験も、それ自体では成功の原因でも失敗の原因でもない。われわれは自分の経験によるショック——いわゆるトラウマ——に苦しむのではなく、経験の中から目的にかなうものを見つけ出す。 自分の経験によって決定されるのではなく、経験に与える意味によって自らを決定するのである」と。
(No.292)
経験への意味付けを間違えてしまうことをトラウマっていうんじゃないのかな?
どのような経験に、どのような意味をつけてしまっているのかを認識しないと、苦しみはなくならないのではないか?
経験への意味付けって例えば、
火を手で触ると熱い。火傷する。という経験。⇒火は手で触ってはいけないんだ、という意味付け
犬に噛まれて怪我をする⇒犬に触ってはいけないんだ、という意味付け
前者は正しい意味付けだよね。火は手で触ってはいけない。でも後者は歪んだ意味付け。犬に噛まれることは無くはないけど、正しく接していればそんなに噛まれることはない。こんな歪んだ認識だと、犬に触れると可愛くて癒されるっていうメリットを享受できなくなっちゃうよね。
カウンセラーなどに頼るときって、昔の経験のことなんか忘れていて、現在犬が怖いっていう悩みを抱えて行くことになる。そこで過去のことに向き合って、あっ、あの時犬に噛まれた経験があって、今怖いんだということに気づく。それがわかれば、常に犬が噛むわけではない、という正しい事実を知ることで、その悩みはなくなっていく。また、当時の詳細が思い出せれば、あっ、あの時、子供だった私は犬の尻尾を引っ張ったな、だから犬は怒って噛んだんだ。そりゃ怒るわ。引っ張らなければ大丈夫だ。と思える。こういう風に治療がすすんでいくのではないか。なので、過去の事実を振り返ることは必要だと思う。
こう考えてみると、トラウマだと思っていたものはトラウマではなくただの経験への意味づけだ、という意味で言えばトラウマの否定は正しいと思う。でもわざわざ、トラウマを否定する、と言わなくても、「トラウマは絶対的なものではなく経験への間違った意味付けだ」と言えばいいことではないか。
では、なぜアドラーはわざわざトラウマを否定するのか?トラウマはないっていう前提を持っていないと、患者がある経験への意味付けを変えるモチベーションをもたないからかな、と思った。間違った意味づけを当然だと思ってしまうから。
上の者が下の者に文句を言わせなくするロジックじゃない?
アドラーの思想通りに生きられれば確かにシンプルになると思う。ただ、この考え方って上の者が下の者に文句を言わせなくするのにとても好都合だと思う。例えば労働者が経営者に「もっと労働環境をよくしてくれ!」って言っても、経営者は「それはあなたの課題じゃないよね。」人の課題に口出すな、って感じで言えちゃう。
自己責任論にもつながりそうな思想です。
とある噂で、アドラー心理学を最初に日本に持ち込んだのは、保守系の思想(たぶん反共産主義的な)の組織だったと聞いたことがあります。
以下のインタビューで著者の岸見一郎氏は以下のように言っています。
「『自己責任』という言葉を他人に言うのは間違っている」『嫌われる勇気』著者に聞いた、“今ここ”を幸せに生きる方法
自分が自分の人生に責任を持つという意味であって、他の人に言ってはいけませんし、言えないのです。
他の人に言わないとしても、この思想を広めていること自体が「自分の人生に責任を持て」と不特定多数の人に言っていることになるのではないか。
哲人冷たいな。青年の気持ちに全く寄り添わない
アドラー心理学を全然知らない人は、最初は自己責任論だと感じてしまうのは当然だと思うし、青年もそういう反応をしている。
青年 先生のお話を聞いていると、「トラウマなど存在しないし、環境も関係ない。なにもかもが身から出た 錆 なのであって、お前の不幸はすべてお前のせいだ」と、これまでの自分を断罪されている気分になってくるんですよ!
哲人 いえ、断罪しているのではありません。
(No.671)
哲人のリアクションが冷たい。「そういう気持ちになるんですね。」って受け止めてあげてもいい気がする。気持ちを受け止めてあげるのさえ、他者との課題の分離ができてないってことになるの?後半の「横の関係」の部分では、「他者に関心を寄せる」ことを主張してるのに。
ゴールから説明しないからわかりづらい
後半になって、「課題の分離」が出発点となり、「共同体感覚」がゴールということが説明される。共同体感覚の説明はかなり後半になってから説明される。
なので、前半がわかりづらくなっている部分がある。青年の本当の目的を指摘するくだりで、
最初から誰とも関わりを持たないほうがましだと思っている。つまり、 あなたの「目的」は、「他者との関係のなかで傷つかないこと」 なのです。
(No.788)
という。これに対して青年は動揺を隠せない反応をするのだが、私だったら「うん、そうだよ。他者との関係を避けるのの何がわるいの?」って言っちゃいそう。共同体感覚がまだ説明されていなこのくだりだと、他者との関係を避けて経済的に困らないようなら別に良いじゃん、合理的じゃん、って思う人も多いと思う。
でも、アドラー心理学では共同体感覚がゴールであり、幸福の源なので、対人関係を避けるというのはよろしくないことなのでしょう。
この本はこのように重要な点を後回しにするのでわかりにくくなっているところが多いように感じた。
努力しろっていう圧が疲れる
対人関係に乗り出すと劣等感を感じることになるが、それ自体は悪いことでなく、健全な努力で補償していけばよいという。でも、現代社会で感じる劣等感は多岐に渡る。仕事、趣味、健康、家族など、無限に出てくるはずだ。いくつかであれば努力で補償することはできる。しかし、時間と体力の問題で、努力しきれない分野も多いだろう。
そんななか「忙しいから努力できない。」ってそのまま正直に言うと、アドラー信奉者からは「劣等コンプレックスだ。」と言われてしまいそう。
なので、対人関係のなかで出てきた劣等感を全てまともに取り扱うというよりは、あまり劣等感を感じないようにする鈍感力のようなもの方が大事な気がする。
アドラー心理学は人生を楽にする部分もあるが、疲れる考え方でもあると思う。
意図してやるのも優越コンプレックス?
ブランド品や権威を使うことが全て優越コンプレックスになるのかは少し疑問。例えば、一部の営業のノウハウ本なんかには、「良いスーツや時計を着て権威づけしよう。」だったり、「広告に有名人を使って売上をあげよう」など指南されていたりするし、実際に一定の効果はある。恋愛においても、地位やお金をアピールすることで、相手の気持ちをひいてうまくいく人もいる。「影響力の武器」という販売心理学の名著でも「権威」という効果を科学的に立証している。
[card name=influence-science-and-practice]

意図してそういうことをすることもアドラーは優越コンプレックスととらえているのかが疑問。
ただ、そもそもアドラーは他者貢献を提唱しているので、あまりに虚像で自分を飾って相手に誤解させて判断させるのはよろしくないのだとは思うが。
個性的なファッションは「安直な優越性の追求」か?
特別な存在になろうとする心理で思い浮かぶのが、個性的なファッションをすること。これは安直な優越性の追求になるのだろうか。この本に出てくる「安直な優越性の追求」の例を見ると、非行など本人や周囲の人に被害を及ぼす行為が該当するのかな、と思う。その点、個性的なファッションはその共同体で制限されない範囲であれば被害を及ぼすわけではないので「安直な優越性の追求」には当たらないと思う。もし、不愉快に感じる人がいるとすれば、それはそう感じた人の課題になる。
とはいえ、いくら個性的なファッションを志向しても、範囲を広げて考えてみれば同じようなファッションをしている人はいくらでもいる、ということを考えれば、唯一無二にはなれないので、結局「普通であることの勇気」は持っていた方がいい。
明らかに個性的なファッションをしている人は、他者から見れば「あー、特別な存在になりたいんだろうな」と思われるだけ。承認欲求を否定すればなんてこともない。
このように、個性を楽しむ行為というのは、アドラー心理学的にはどんな意味があるのか、と疑問に思った。「安直な優越性の追求」にも当たらないが、かといって、共同体へ貢献しているわけでもない。純粋に自分だけの楽しみだ。好きな音楽を聴いたり、趣味を楽しむことについても。貢献感ではないかもしれないが、自由意志ではある。
この本では、貢献感を幸福の源泉とするが、自由意志も重視していると思う。感情に支配されたりなどして自由意志を失うことを戒めている。では、貢献感と自由意志はどのような関係があるのだろうか。
もしかしたら、主観的な貢献感を得るためには自由意志が必須ということかもしれない。自由意志なき”貢献感”は、実は貢献感ではなく奴隷的な労働や搾取なのかもしれない。その自由意志をしっかりと確認し、盤石にするために個性、芸術、趣味を楽しむ営みが必要なのかもしれない。
他者と比較をするかを都合良く切り替えろということ?
対人関係に乗り出すと他者との比較のなかで劣等感が生まれ、それは健全なものだという。しかし、優越性の追求をするにあたり、健全な努力をする際には、他人と比較するのではなく、理想の自分と比較しよう、という。
矛盾しているな、と最初思ったが、どこかで他人と比較するかどうかを切り替えるということだと考えた。でも、そんなに都合良く切り替えられるの?と思う。どのような心理状態でこのような切り替えを行うのかもっと詳しく説明して欲しかった。
この本では他にも矛盾するようなところがり、それは全て「切り替え」を前提としているんだろうなと思っている。でもその切り替えを一貫性を持って行うのが難しいので、その心持ちを説明してほしい。
あと、対人関係のなかで劣等感が生まれる、というのと「課題の分離」という考え方は矛盾しているようにも感じる。例えば、「Aさんはあんなに稼いでいるのに私はこれしか稼いでない。健全な努力をしよう。」っていうのが劣等感で、この本では悪いものとはされていない。でも、「課題の分離」という考え方だと、どれだけ稼ぐかってのはAさんと私それぞれの別の課題。Aさんと同じくらいは稼ぎたい、って思っちゃう時点で課題の分離ができてない気がする。私の人生ではなく、Aさんの人生を生きることになる。
スポンサーリンク
2つのモードを行き来しろということか?
このような矛盾していると思われる点を、好意的に捉えて矛盾ではないとすると、モードが二つあるのかなと思った。「A.人間の自然な状態」と「B.アドラー的な心理状態」の二つ。
Aは、承認欲求については人間が自然に持つものとして「傾向性」と呼んでいるが、アドラーはこれを乗り越えろといっている。つまり、AからBになれと。
そして、劣等感が生まれる他者と比較してしまう状態もAに含まれると思う。そこで優越性の追求によって他者との比較をやめてBになれ、と言っているのだと思う。
アドラーは承認欲求については完全に否定しているが、劣等感、つまり他者との比較を完全に否定しているようには読めない。だからややこしい。Aについては完全に否定し、Bだけの状態を目指せ!って言ってくれた方が楽だ。
とはいえ、個人的にはBだけになると人間味がないように思うし、劣等感こそアドラー的な人生のモチベーションになっているようにも読める。AとBを行き来するっていうことなのかなと思う。
もう一つの考え方としては、一人の人間には常にAとBが並存していている。そして、Aは常に劣等感などの自然な感情を生み出している。「わたし」はその感情を常に野球のキャッチャーのようにキャッチして、Bに渡してあげる必要があるのかなと思った。
ここまで考えてふと思ったが、承認欲求と他人との比較って同じことなのかもしれない。自分の価値を外部の指標を使って計るという意味で。
言葉の力を信じろっていうけど
権力争いを挑んできた人には、怒りという道具に頼らず、言葉の力を信じようというが、言葉だけでやめてくれるのだろうか?「私は怒っている、悲しんでいる」など感情面を伝えないと何も伝わらないのではないか?感情面を伝えるとなると、声色、表情などにその感情をある程度のせたほうが伝わると思う。
哲人は相手がやめるかどうかは相手の課題だというかもしれないが、面罵され続けることを許容するということか。自分からその人との距離を置けということなのか。そうすると、必要があって行っている場所に行けなくなってしまうではないか。権力争いを挑まれる度に行ける場所が減ってしまう。
正しいと思っているのに謝る方が不誠実ではないか
哲人は正しいと思っても主張しないようすすめる。
あなたが正しいと思うのなら、他の人がどんな意見であれ、そこで完結するべき話です。
(No.1334)
また、誤りを認めたり、謝罪をすすめる。
でも、正しいと思っているのに、誤りを認めるのは、不誠実だし、のちのち余計な誤解を引き起こすのではないか。
そもそも「嫌われる勇気」という承認欲求を否定する考えと矛盾しているように思う。
善悪や道徳の問題ではないっていうけどほぼ善悪語ってるじゃん
青年が糾弾されているような気持ちになるというと、アドラーは善悪で語っていないという。
アドラーは、人生のタスクや人生の嘘について、善悪で語ろうとはしていません。いまわれわれが語るべきは、 善悪でも道徳でもなく、〝勇気〟の問題です。
(No.1526)
善悪や道徳で語らないということは、つまり選択肢がいくつかあればそれは対等でどれを選んでもいいってことだと思う。
でもどう読んでもある生き方は悪である生き方は善と見ているようにしか見えない。人生の「嘘」や人生のタスクの「回避」や「勇気」という言葉に、もはや価値観が出ちゃってる。
道徳や善悪と勇気は違うというかもしれないが、どう考えても勇気が無いことは悪だし、勇気があることは善だ。哲人も以下のように、アドラーが価値について語っていることは否定していない。
心理学は科学であるべきなのに、アドラーは「価値」の問題を語り始めた。
(No.2814)
以下から、善悪と道徳は違うという意味なのかもしれない。
ギリシア語の「善」(agathon) という言葉には、道徳的な意味合いはありません。ただ「ためになる」という意味 です。一方、「悪」(kakon) という言葉には、「ためにならない」という意味 があります。
(No.528)
つまり、哲人は
価値=善悪≠道徳
って認識だと思う。
じゃぁ、道徳って何?って考えた場合、宗教的な意味合いになるのかなと思う。神の意志とか。
仮に哲人の言っている通り、アドラーは道徳(神の意志)を語っておらず、価値(ためになる)しか語ってないとしても、「お前はためにならないことをしている。」と言われれば糾弾されている気になるのは変わらないと思う。
しかも、共同体感覚のくだりで、共同体の範囲を宇宙や無生物まで含みうる、ということを言っているので、もはやそれは神の意志と変わらないのでは、と思うので、ほとんど道徳的な話をしていると思う。
本当の意味で、このテーマで、道徳を語っておらず、フラットに選択肢だけ示している本があれば読んでみたい。もしくは、糾弾してないというのではなく、正直に「そんな生き方をしているあなたはバカだ。」とはっきり糾弾してくれたほうがわかりやすいのに、と思った。
所有の心理学と使用の心理学とビジネス
よく新規ビジネスのアイディアを考える際に、自社が持っているリソースから考えるのではなく、生活者がどのようなものを求めているのか、から考えよう、という。
これは「何が与えられたか」(所有の心理学)と「与えられたものをどう使うか」(使用の心理学)の違いに相当すると思う。
生活者が求めているものがわかれば、それにむけて自社が持っているリソースを使う。
使用の心理学はこう言ったほうがいいのではないかなと思う。
「与えられたものを何にどう使うか」
「何に」というのがないと、「どう」使うかというのも決まらないので。これは英語で言ったほうがわかりやすいですね。つまり、
What do I have?
ではなく、
How do I use what I have?
って本にはあるけど、
For what and how do I use what I have?
って方がいいと個人的には思う。
ビジネス以外でも同じで、共同体の何に貢献するのかっていうのを考える必要があると思う。
そして、「何に」よって焦点を当てる「与えられたもの」は変わるのかなと思う。
例えば、あなたはある自動車メーカーの社長だとする。その会社はスピードのある車を作る技術を持っている。しかし、世の中の生活者はスピードではなく燃費の良さを車に求めていることがわかったとする。そうなると、「与えられたもの」は「スピードのある車を作る技術」ではなくなる。単純に「車を作る技術」でしかなくなる。
もしくは貢献する対象の生活者をよりニッチな「スピードを求めるユーザー」に変えるということも考えらる。しかし、ビジネスだと自分のリソースに合わせたユーザーを探すのは悪手な気がする。その後も自分を変えようとせず、ユーザー側を変えるようになり、結局一人もユーザーがいないという状況に陥るため。
なので、やはり、「与えられたもの」は一旦忘れ、「何に」を考えるのが大事だと思う。
主観の貢献感と現代の客観的なデータ重視は両立するか?
共同体感覚を得るには主観で貢献感を感じられればよいということだ。しかし、現代のマーケティングでは客観的なデータを重視する。売上、ページビュー、来店数など。ビジネスと私生活は違うという人もいるかもしれないが、現代では日常生活にもマーケティング的な考えを応用するのは普通になっている。婚活などもそうだろう。マーケティング的な感覚がない行動は、独りよがりだったり、自己満足的などと批判される対象になるのが一般的ではないか。それに対し、この本で主張される主観で貢献感を感じられればいいというのは、呑気すぎるきらいがある。この本の考え方とマーケティング的な考え方は両立できるイメージが持てない。
物語は不要?販売、就活、婚活でも物語が求められる現代
この本では、物語は不要とされる。しかし、現代社会では至るところで人を説得するための物語が求められる。商品を販売するために、その商品の背景などの物語を語る。これは一般的にブランディングと言われる。就活でも履歴書や面接で個人のキャリアストーリーを伝えることが求められる。婚活でさえも、支離滅裂で理解不能な人生ではダメで、ある程度相手に理解できる筋書きが必要となる。
確かに自分一人で生きていく分には、物語なんて意識しない方がすっきりして生きやすい。しかし、人と関わりたいなら、相手に理解してもらえる物語がないと、気味の悪い存在になり果ててしまうだろう。結婚できなくても死にはしないが、商品が売れなかったり、就職できなければおまんま食えない。「相手に伝わらないのは相手の課題だ!」とか言って超然としているわけにもいかない。
このような社会状況のなかで、この本の「物語は不要」という考えを貫くことはできるのだろうか。ここまで考えると、「物語を作って語ってもいいが、自分はそれを信じるな」ということかなと思った。自分で作った物語を人には語るが信じないということだ。自分はあくまでむき出しの「いま、ここ」にしか集中しないが、人には物語という砂糖でくるんだ情報を語る、ということ。
ここに誠実さがあるのかわからないし、詐欺師か二重人格にならないと難しい気もする。この本で良いとされる「対等な横の関係」と言えるだろうか。物語など信じてしまう相手を下に見ていることにならないだろうか。
競争社会、市場社会に染まった思考の中和剤か?
承認欲求の否定は、市場からの評価を意識するように馴らされた現代人には驚くような考えだ。また、他者との比較ではなく理想の自分との比較して優越性の追求しよう、というのは競争社会の考え方に染まった人には慣れない考え方だろう。
この本が現代社会で必要となる考え方とは合わないのでは?と最初考えていたが、そうではなくそういう考え方に染まって苦しんでいる人のための中和剤のような機能を果たしているのかもしれない。
前述した、現代では客観的データが求められるのにこの本は主観を重視していたり、物語が求められるのにこの本では物語をひていしてる、というのも、同じかもしれない。
つまり、現代社会で求められる考え方に適応するがゆえに生まれる苦しみを緩和するのがこの本の役割なのかもしれない。
なので、競争社会や市場社会になりきっていない国であれば、この本はそこまで受け入れられないのではないか。
人を自分の思う通りに動かすのではなく思う通りに動く人を探すのはいいのか?
承認欲求の否定、課題の分離という原則のなかで、相手を自分の思う通りに動かすことはしない。
もしもあなたが「他者の期待を満たすために生きているのではない」のだとしたら、 他者もまた「あなたの期待を満たすために生きているのではない」 のです。相手が自分の思うとおりに動いてくれなくても、怒ってはいけません。
(No.1682)
ビジネスで行われていることは、こちらの商品を相手に買わせるということ。とはいえ、現代のビジネスでは、欲しくない人に無理に買わせるというよりは、欲しい人を探して買ってもらう、という営みの方が多いように思う。マーケティング調査によって、消費者の層を分割して、自分の商品を欲している層をみつける、というように。
ビジネスでなくても、人を思い通りに動かすのではなく、思い通りに動いてくれる人を探す、というのはアドラー的には良いのだろうか、という疑問が浮かぶ。
ただ、思い通りに動いてくれる人を探す、というのは、よく考えると「所有の心理学」な気がしてきた。相手にしてほしいことの内容を変わらないものとして考えているから。しかも、誰かがそう動いてくれないなら、他の人もそう動きたくない可能性が高く、永遠に探さなくてはならなくなる。動いてくれない人をどんどん切り捨てていくことになり、焼畑農業のようになる。どんどん新規の知り合いにアプローチするので、アプローチできる対象が減っていくことになる。切り捨てた人が敵になってしまう可能性もある
やはり、こちらがしてほしいことをしてもらうのではなく、相手がしたいことをしてもらう、っていうのが本筋なんだと思う。でも、そう考えると、純粋に人にしてほしいことをしてもらうこと、って無理だということになり、少し暗い気持ちになる。
もし何かを人にしてほしいなら、それをしたいと思ってもらわなければならない。そのためには、
- 交換条件に合意する(金銭や便益)
- してあげたいと思う人物になる
1はビジネスそのものなので、難しくない。
難しいし重要なのは2だ。2を叶えるには、結局相手に好かれなければならないと思う。そうなると、嫌われる勇気、承認欲求の否定と相反してしまうことになる。
アドラー的な生き方をするなら、ビジネス以外で人に何かをしてもらう、ということは考えるべきではないということかもしれない。例えば「友達になってほしい」「恋人になってほしい」といった願いは持つべきではない、ということかもしれない。正直、非常につまらない人生ではないか。
それなら、この本で、哲人は「自分は幸福だ」と言っているが、「この世はくそつまらないものだ。」と言ってくれた方がわかりやすい。
それとも、「この世はくそつまらないものだけど、期待しなければたまにはいいことあるよ。」っていう意味で「幸福だ」と言っているのか。それならそう正直に書いてほしい。
課題の分離はそんなに簡単じゃない
誰の課題か見分ける方法はシンプルで、「その選択によってもたらされる結末を最終的に引き受けるのは誰か?」であるという。
しかし、そんなにシンプルだろうか?
例えば上司が部下に介入するケースを考えてみる。その仕事がうまくいかなければ、業績にかかわるので、上司も、そしてその会社から給料をもらう部下も結末はどちらも引き受けることになる。
体育会系的な文化を持つ組織の場合、先輩が後輩に責任を押し付けてくるような文化のもある。その場合、どう課題を分離をすればいいのだろうか。組織を離脱するしかないのではないか。
また、本文中に、上司が理不尽に怒りをぶつけてきた時は、それは上司の課題。上司が始末するべき、とある。しかし、怒りがをぶつけられることによって、こちらの仕事が進まなくなればこちらの課題になるのではないか。その場合はどのように対処すればいいのか?
スポンサーリンク
課題を分離したら、助けを求めにくくならない?
最近は、助けて、と人に言えずに、心を病んでしまったり、自ら命を絶ってしまう人もいる。ビジネスでも、早めに助けを求められないために、手がつけられないほど問題が大きくなってしまうことも多いと聞く。
ここまでは私の課題、ここからはあなたの課題としてしまうことで、さらに相手を頼りづらくなってしまうのではないか。現代の人に求められるのは相手を頼る力ではないか。自分の課題に人にも関わってもらう方が重要ではないか。
Takerにはどう対応すればいい?
見返りを求めるのは課題の分離とかけ離れた発想という。しかし、こちらがGIveし続けるのを当然のように受け続ける人、つまりTakerにはどのように対応すればいいのか。
本書では共同体に貢献することが良しとされる。なので、こちらとしては何かをGiveしようとする。しかし、一部の全くGiveをしない人にそれを無為に搾取されてしまうのは悲しい。
TakerだとわかったらGIVEを停止すればいいのか。
ちょっとした欲望に答えるGIVEはせずに、根源的に必要としているものをGIVEしないとだめなのかな。そのためには、相手が何を必要としているか見極める時間が必要なのかも。すぐに与えてはいけない、ということか。なぜすぐ与えたくなるかというと、やはりよく見られたい、好かれたいという気持ちを抑えられないから。この辺にも嫌われる勇気は関わってくるのか。
ここで思い出したのが「7つの習慣」という本の「Win-Win以外はNo Deal」という考え方。Win-Winにならないなら、無理に取引しないということ。やたらめったらGiveするのではなく、納得する条件にならなければ取引しないということが大事なのかもしれない。きちんと相手の求めていることと、こちらが得られるものを見定める期間が必要なのだろう。すぐにGiveしてしまう癖がある人は注意したい。
「嫌われる勇気」って表現、語弊がないか?
タイトルの「嫌われる勇気」だったり、哲人の「自由とは、他者から嫌われることである」と言う言葉は語弊がある気がする。
二つの選択肢があるとして、一つは好かれる行動、もう一つは嫌われる行動。他の条件が同じなら、後者を選ぶということになる。
結局哲人は「嫌われることを恐るな、といっているのです。」と少し表現を変える。つまり、あえて嫌われることをしろといっているのではない、ということ。
なので、タイトルとかは語弊があると思うし、「嫌われることを恐るな」にしちゃうと「普通のこと言ってるなー」としか思えない。でも、以下のようにも言っている。
あなたが誰かに嫌われているということ。それはあなたが自由を行使し、自由に生きている 証 であり、自らの方針に従って生きていることのしるしなのです。
(No.2051)
もし、わたしの前に「あらゆる人から好かれる人生」と「自分のことを嫌っている人がいる人生」があったとして、どちらか一方を選べといわれたとしましょう。わたしなら、迷わず後者を選びます。他者にどう思われるかよりも先に、自分がどうあるかを貫きたい。つまり、自由に生きたいのです。
(No.2076)
これを読むとやはり、嫌われるようなことをしろって言ってるように読めるんだよな。これまで過度に好かれようとして生きてきた人には、これくらい言ったほうがいいって言う意味でこのような強めの表現なのかな。
「嫌われる」のと「承認されない」って同じかな?
「承認欲求を持つな」と言われれば、「そうか。そうしよう。」と思えるんだけど、「嫌われろ」って言われると「ん?」ってなる。
承認されなくてもいいから、普通に人として接してほしいくらいには思ってしまう。嫌われるっていうのは、邪険に扱われたり、見下されたり、ひどいことを言われたり、と言うことだと思うので。
なので、「嫌われる」と「承認されない」って同じ?と言う疑問が生まれた。
私の常識感として、全く承認していない人にも邪険には扱わないし、丁寧に接する。しかし、一般的にそうではないのかもしれない。つまり、一般的には、承認していしる人以外は、邪険に扱う、見下す、などは当然のことなのかもしれない。
私は初対面の人などに、邪険に扱われると、敵意を持たれたかな、嫌われているのかな、と思ってしまっていたが、承認されていないだけか、と思えば、もう少し気楽になれるかもしれない。
他の成功哲学の本だとほめることや協調性を重視してるんだよなー
以下のようにデール・カーネギーやスティーブン・コヴィーもアドラーに影響を受けたとされています。
世界的ベストセラーの『人を動かす』や『道は開ける』で知られるデール・カーネギーも、アドラーのことを「一生を費やして人間とその潜在能力を研究した偉大な心理学者」だと紹介していますし、彼の著作にはアドラーの思想が色濃く反映されています。同じく、スティーブン・コヴィーの『7つの習慣』でもアドラーの思想に近い内容が語られています。
(No.194)
ただ、「人を動かす」は、「相手とぶつかるな」だったり「人をほめろ」というように、人との協調性を重視して人に嫌われないようにするような考え方が中心だと私は考えている。なので、承認欲求を否定したり、相手を評価しないなど、アドラーとは全く逆だと思うのだが、どう影響を受けたのだろうか。
「7つの習慣」の第一の習慣の「主体的である」など、とてもアドラー的な考え方が散見される。

ただ、第二の習慣の「終わりを思い描くことから始める」はどうだろう。以下に紹介した、「思考は現実化する」などのさまざまな成功哲学本でも「目標を明確にしよう」と説いている。しかし、アドラーは「目標などなくてもいい」と、真反対なことを説く。
[card name=think-and-grow-rich]


これは非常に悩ましいが、個人的には目標を決めることは必要だと思うし、アドラー的な考えと共存もできると思う。目標を決めるのが必要という理由は、例えば、朝、会社に出勤する際、アドラーのいうとおり、「いま、ここ」だけにしか集中していなければ、家を出た瞬間、「あれどこ行くんだっけ?」ってなると思う。ちょっとしたことだけど、「会社」という目標を意識しなければ、会社にたどり着くことはない。なので、何かしら「目標」があって「いま、ここ」があるんだと思う。
どう考えればいいかというと、以下で紹介したエッセンシャル思考という本が参考になる。
[card name=essentialism]

要は目標を考える時間と、作業をする時間を分けるということだ。目標を考える時間は、それはそれで「いま、ここ」に集中している。「目標を考える」という作業に集中しているからだ。目標が決まったら、それにむけて目の前に作業に集中する。こうすることで、常に「いま、ここ」にスポットライトを当てた生き方になる。「嫌われる勇気」では詳しく書かれていないけど、アドラー的な考え方ってこういうことなのではないか。
ただ、「思考を現実化する」では願望がすでに実現しているときのイメージを潜在意識に流しこむ「深層自己説得」という手法が勧められている。これは「嫌われる勇気」でいう優越コンプレックスにつながる行為ではないか。
自己肯定とは、できもしないのに「わたしはできる」「わたしは強い」と、自らに暗示をかけることです。これは優越コンプレックスにも結びつく発想であり、自らに嘘をつく生き方であるともいえます。
(No.2875)
ここは個人的にどう考えていけばいいのかな、と悩んだ。「嫌われる勇気」で勧められているありのままの自分を受け入れる自己受容と、深層自己説得は逆な行為だ。
まずは自己受容をして、その段階で願望や目標を現実的な努力をする前提で可能なものに設定するということかもしれない。現実的な努力で可能な願望や目標であれば、深層自己説得しても優越コンプレックスにはならずに、健全な優越性の追求になると思う。
そして、一旦設定した願望や目標が、途中で非現実的だとわかったら、その時点で自己受容をし、もう一度願望や目標を調整し深層自己説得しなおせばよいということかもしれない。つまり、柔軟に自己受容と深層自己説得を行き来するということ。
つまり、「思考は現実化する」は特に優越性を追求するフェイズについて語っている本だと思われる。
「勇気づけ」って「操作」じゃない?
この本では、良好な人間関係を築くために、縦の関係に基づいて、ほめたり叱ったりするのではなく、横の関係にもとづく「勇気づけ」を推奨している。
ほめたりしかったりすることは相手を操作することに繋がるからよくないということだが、勇気づけも操作ではないか?というのは、相手が課題に向き合うための勇気を持ってもらうために、素直な感謝を伝えるというのも操作であると感じる。確かに素直な気持ちかもしれないが、意図して行うことだし、「勇気づけのアプローチ」という言葉の「アプローチ」という言葉が操作感がある。そもそも、相手が課題に向き合う勇気をつける、というのが課題への介入に他ならないと思う。
そこで、こう考えてはどうか。誰かと良好な関係を築こうとすること自体が操作だ。なので、全ての他者に素直な感謝を伝える習慣をつけよう、という方がわかりやすい。相手ではなく自分側が変わる、っていうこと。
素直になったとして都合よくポジティブな感情だけ伝えられる?
勇気づけの方法として、素直な感謝の気持ちを伝えるとある。私の場合、素直になってしまうと、もちろん、感謝している時は感謝の気持ちを伝えられるが、腹が立った時や困惑した時などはネガティブな感情を伝えてしまうかもしれない。どうして、そうポジティブな感情だけを選択して伝えられるのだろうか。素直というのは選んだ時点で素直ではなく、意図が入っているのではないか。本当の意味で素直になるのなら、ネガティブな感情も表に出てしまっても仕方ないのではないか。
そういうネガティブな感情を表に出さないために、素直さを失っている人が多いのではないか。
場合分けして考えてみた。
・ポジティブな感情が浮かんだ場合
素直なら⇒感謝
素直ではないなら⇒評価
・ネガティブな感情が浮かんだ場合
素直なら⇒直接的なネガティブな言葉
素直ではないなら⇒評価
となる。一般的には、ポジティブな感情が浮かんだ場合は素直になり、ネガティブな感情が浮かんだ場合は、素直でないのが、良いマナーとされるだろう。
つまり、ネガティブな感情が浮かんだ場合、素直にネガティブな言葉を直接的に相手にぶつけるよりも、引いた視点で評価的に伝えた方が、摩擦が少ないと。
「私はあなたのさっきの振る舞いに怒っている」
「あなたのさっきの振る舞いはマナー違反だ」
後者の方が大人な言い方とされる。
でも、よく考えたら、ネガティブな感情の場合も素直になって、相手に直接的にぶつけるほうが、良い気がしてきた。評価的に伝えるほうが、操作の意味合いが強くなり、縦の関係になるからだ。
ただ、本当に直接的にネガティブな感情を伝えるなら、言葉の言い回しよりも、声のトーンや表情などの非言語の方が大事な気がする。それはポジティブな感情の時もそうだが。
この本は、人に罵倒された時は、「怒りという感情に頼らずに言葉を使おう」というが、ポジティブな時は素直な感情を伝えるのに、ネガティブな時は感情ではなく言葉を重視するのが、非対称的で分かりづらく、テクニック的に感じる。
ここまで考えて思い出したが、目的論だ。
ネガティブな感情を直接的に、例えば声のボリュームを上げてにらみつけて伝えることを、哲人は「怒鳴るために、怒った」というでしょう。怒りを捏造したと。
一つ思考実験をします。青年が困っている時に誰かに助けてもらった場合、めちゃくちゃ笑顔で感謝の言葉を伝えた場合、哲人はどういうでしょう。
「笑顔で感謝の言葉を伝えるために、ありがたいという感情になった。ありがたいという気持ちを捏造した」というのでしょうか。そうは言わないでしょう。素直な感謝な言葉を伝えるのを奨励しているので。
こう考えると、怒りを伝えるのは目的論で解釈するのに、感謝を伝えるは目的論では解釈しない、ということ。ダブルスタンダードではないか。
二種類の感情を伝えるという行為で、解釈の仕方が違う理由を考えてみた。感謝の場合は、相手によく思われ、怒りの場合は相手に悪く思われる、という違いとしか思えない。そう考えると、この教えは承認欲求を肯定してしまっているのではないか。処世術的なテクニックなのかな、と思ってしまう。
あぁ、でも感謝を伝えるのも目的論で解釈してもいいのかな。「笑顔で感謝を伝えるために、ありがたい気持ちになった。ありがたい気持ちを捏造した。」これをしようっていうのが、勇気付けなのかな。でも、捏造って「すなお」とは違う気がするんだよな。
ここで、思い出したのがデール・カーネギーの「人を動かす」。「どんどんほめよう」的な教えで、アドラーと真逆と思っていた。でもアドラーも感謝の気持ちを捏造してどんどん感謝を伝えよう、っていうことだとしたら、実は二つの本は近いのかもしれない。
貢献感を目的論で解釈するとどうなる?
共同体に貢献して共同体感覚を得るのが良いとされている。
感情に動かされた行動を目的論で解釈する例にならって、これを解釈すると
共同体に貢献するために共同体感覚を捏造した、といことにならないか。捏造できるくらいなら、わざわざ行動しないでも、この感覚だけ捏造して幸福になってしまえばいいのではないか。
ここまでくると、捏造とされる感情と捏造されない感情がある気がしてきた。どういう違いがあるんだろう、と思うと、社会と調和できるかどうかなのかな。怒りは社会と調和しにくいから捏造されたとされ、感謝や貢献感は調和しやすいから捏造とはされない、ということか。
だとしたら、そういう説明の方がわかりやすい。「社会と調和しない感情は捏造したと考えろ」と。でも後半で哲人はこんなこともいう。
悲しいときには、思いっきり悲しめばいいのです。痛みや悲しみを避けようとするからこそ、身動きが取れず、誰とも深い関係が築けなくなるのです
(No.2994)
ここでは、悲しみという少し社会と調和しにくい感情を目的論で解釈せず、捏造とは言っていません。先ほどの怒りとは何が違うのでしょうか。
感情の先にある行動かな。怒りの場合は他者に怒鳴るという行動。悲しみの場合は、悲しむという他者とは関係ない行動。つまり、他者と調和しない行動につながる感情は捏造とする。というか、結果的にそういう行動につながらなければ捏造とはしない、ということ。
これは結局何が言いたいのか考えた。つまり、単純に「社会と調和しない行動をするな。そういう行動をする言い訳は全て認めない。」ということ。
感情と理性を分けない「全体論」を言いたいんだと思うんだけど、「全体論」を主張するのはなぜか、と考えると、感情と理性をわけちゃうと、感情を言い訳に色々とよろしくない行動をしてしまうので、最初っから感情と理性は一体と信じ込んでしまった方が、より良く生きれるということだろう。
なぜフロイト的な心理学を否定するか少しわかった。感情を分離して自分の感情を外から分析する心理学だ。感情を外から見つめていたら、全体論を信奉することはできないだろう。
ここまで考えると、アドラー心理学は、率直に言っちゃいたくなってきたけど、「自分のダメな行動の言い訳するな!っていうすごくマッチョな思想。」テクニックなんて書いてない。回りくどく具体的なノウハウがありそうに書いているのがずるいと思う。
ダメな行動というのは、たぶん共同体に貢献しない行動だろう。つまり
「共同体に貢献しろ!貢献してない行動の言い訳をするな、っていうすごくマッチョな思想」だと思った。
青年は感情を否定するなら人間は機械になってしまうという。哲人は感情に支配されて自由意志を否定するのが機械であるかのようだという。ここには人間対機械という対立があり、当然だが青年も哲人も人間は機械よりも人間である方がよしとしている。では人間らしいのはどっちなのだろうか。感情に動かされる方か、自由意志で動く方か。
もちろん哲人は感情を全否定しているわけではなく「人は感情に抗えない存在」ではない、としているだけ。であれば、感情に抗う方法をもっと詳しく説明してくれればいいのに、と思う。
そこで自由意志とは何か。自由意志を生むものは何か。それは感情じゃないのかという気がしてしまう。
何にも依存しない自由な意志って神の意志くらいじゃないのか。神の意志を人間も持っているということかな、という気がする。ニーチェの言葉「神は死んだ」を思い出した。アドラーはニーチェから影響を受けたとされる。身体、感情などの障害物はあるが、意志自体は神と一緒で自由だ、ということか。ただ、共同体感覚を志向するという条件はつくが。神の意志もきっと共同体感覚を志向しているはずだから、そこはかわらないか。やはり、身体や感情があるというのが違いか。
ここまで考えると、身体や感情を共同体より下に置く意味は無いと思う。なので、身体や感情と共同体を分けて考えている意味もない気がする。全てが調和すればいいのではないか。少し仏教的な感じになる。頂点が無いという意味で。ただ意志だけは分離しているので、それが頂点になるのか。意志まで統合されていると考えてしまってもいいのだろうか。
評価と感謝ってそんなに違うの?
他者には評価ではなく素直な感謝をすることで勇気づけを行うとある。また共同体感覚、つまり貢献感は、他者の評価からではなく役に立っている主観的な感覚から生まれるという。
疑問なのは、評価と感謝ってそんなに違う?ってこと。例えば、SNSで「いいねボタン」が「ありがとうボタン」になったとしても本質は何も変わらないだろう。
また、上司ができる部下に対して感謝の言葉を伝えるはほめるのと何が違うのか。アドラーが重視する共同体感覚とは、主観によって「わたしは他者に貢献できている」ことだ。
「今回の君の仕事ぶりには助かったよ。」と言われても「今回の君の仕事ぶりはすばらしいよ。」と言われても、どちらでも貢献感を感じられる人もいるだろうし、どちらでも感じられない人もいるかもしれない。
結局大事なのは、「本当に役に立てた?」ってことだと思う。「助かったよ」でも「すばらしいよ」でも、素直ではなく何か別の目的を持って言っている場合は、貢献感は感じられないだろう。もっとやる気を出させようとして言っているんだなー、という裏の意図の方が感謝の気持ちよりも強く感じられたら「助かったよ」でも貢献感は感じられないだろう。
他者に自分の貢献の確認を任せるのではなく、その確認は自分でやるってことだと思う。人にほめられて簡単に喜んでしまうのは、貢献の確認を人任せにしていることだと思う。
そう考えると、相手の言葉も大事だが、行動に注目することが重要だ。上司と部下の場合は、例えば、任せてくれる仕事のレベルが上がる、給料を上げてくれる、やめようとしたら引き止められる、など。営業マンと顧客の場合は、実際に売上が上がる、などであろう。もちろん、言葉からわかる本音もあるが、行動がそれを裏付けるということだ。
行動というのは数値で見ることができる、売上、来店数、ページビューなど。もちろん数値化できないものもある。声のトーン、笑顔の質、など。もちろん現代の音声解析や画像解析を使えばそれらも数値化できるだろう。
数値ではなく、人間の五感で感じられればそれでもいい。それが主観で感じるということだと思う。大事なのは、貢献がわかる生の情報だろう。他人に編集されていない生の情報ということだ。そう考えると、他者の評価であっても、一人ではなく多くの人のものを総合すれば、「編集され度合い」は減って生の情報に近づくとも考えられる。
とはいえ、この本では「目に見える貢献でなくもていい」というのでよくわからなくなる。何の拠り所もなく自分は役に立っている、と勝手に思っていいということだ。この考えだと、勝手に貢献していると思い込む自己満足おじさんになってしまわないか心配だ。
これはどう考えるのがいいのか。自分が貢献している証拠探しにあまり必死になるな、ということかなと思った。人に勇気付けを行うときは、こういう情報を提示するのが有効だが、自分のためにそういう情報探しはしないほうがいい、ってことかもしれない。そういう情報で貢献感を感じられるかもしれないが、それを自分から探そうとまでするのは他者の人生を生きている感じがある。こう考えてくると、ますます評価と感謝の違いがよくわからなくなる。
それに、生の情報で相手に貢献できていると主観で感じられていても、より大きな共同体のレベルで考えたら、マイナスの貢献をしている場合もあるだろう。例えば、会社である部署の売上には貢献できたとしても、他の部署の売上を食ってしまっていて会社全体の売上は減ってしまっていたり。また、会社の売上に貢献したとしても、地球環境を汚染してしまっていたり。
なので、生の情報、自分の感覚、思想、良心を用いて総合的に感じるものなのかもしれない。評価はダメで感謝は良いと単純にこの本の中で言われているのは、これに気づかせるための入り口に過ぎないのかなと思う。
対等な横の関係を目指すのに自分にだけ厳しい考え方
縦の関係ではなく、対等な横の関係を作るのが良いとされている。その方法として、すなおな感謝な気持ちを伝えるなどの勇気づけという手法がすすめられる。
それなのに、自分の貢献は目に見えないものでもいい、などと暗に確認をよしとしないように言っている。当然、承認を求めるのは否定されている。これって対等って言えるのかな。
以下で言われているように、まずはこちらから始めろってことなのかもしれない。
他の人が協力的でないとしても、それはあなたには関係ない。わたしの助言はこうだ。あなたが始めるべきだ。他の人が協力的であるかどうかなど考えることなく
(No.2702)
ただ、「始める」という言葉に違和感がある。この言葉には「始めた」後に、他の人が2番目、3番目と続くイメージだ。これは他者に期待していて、課題の分離に反しているのではないか。
そもそも、「対等な横の関係」という言葉自体、相手に対等に接するように期待している言葉ではないか。ここは、こちらからは対等に接するが、相手からどう扱われるかは気にしない、という意味なのか。でも、対等に接してくれない相手と関係を続けたいと思うことはないので、こちらから関係を断つことになる。この本でも関係を断つことは自由とされているので。
それとも、「対等な横の関係」は相手に何かを期待している言葉ではないということか。つまり、相手に対等に接するのは、人として当然の振る舞いであり、公共の場で服を着るレベルの基礎的なことということか。なので、対等な扱いは相手に期待してよくて、こちらも対等に扱っているのに相手が対等以下で接してきた場合は、関係を切るのは何の問題もない、ということか。
いや、しかし、相手から対等な扱いを期待するのはやはり間違いという気がする。というのは、相手はアドラー心理学なんて学んでおらず自然な傾向性に身を任せている人がほとんどのはずだ。というのは、そうでなければこの本はこんなに売れていない。なので、多くの人はこちらに承認を求めてきたり、評価してきたり、課題に介入してきたり、逆に相手の課題に介入させてきたりする。これは対等だと言えないのではないか。つまり、こういった本で、相手を人として尊重した扱い方を学べば学ぶほど、相手のこちらへの接し方とのレベルの差ができてしまい、対等な関係とは遠くなってしまう。そういう状況でどうしたら対等な横の関係を作れるのだろうか。正直この本を読んで悩んでしまう問題だ。
一つの可能性としては、行為のレベルと存在のレベルの考え方だ。相手のこちらへの接し方は行為のレベルと言えるが、相手に存在のレベルで感謝できるか、ということだ。仮に対等に接してくれなくても、存在自体に感謝できればいい、ということだ。これはヒモに搾取されるみたいな情けない関係に思える。相手に対等に接してもらえないが、存在がありがたいので関係を維持する、といいう意味で。こういう関係を維持する場合、相手がこちらを評価してくるのは気にしない強いメンタルを持てばいいが、相手がこちらの課題に介入してきた場合は、介入させないようにしなければならない。その過程で衝突して関係が崩れる可能性は出て来るが。
スポンサーリンク
ハレとケ。普通の日常を生きろ
この本では「普通であることの勇気」が推奨される。歴史に名を残したり、高邁な理想などを目指して特別になろうとするのではなく、「普通の自分」を受け入れようという。これは、「いま、ここ」とはかけ離れたものを見て現実逃避的な視野になることを戒めているように思った。
ここで「ハレとケ」という概念を思い出した。ハレは祝祭や儀式を表し、ケは普段の日常生活を表す。ケが続く中に、たまにハレがあるぶんには問題ない。しかし、それが逆転し、ハレばかりになってしまうと、人生は狂ってくるだろう。ハレには魅惑的な魅力があるので、ついつい人生の中心に据えてしまいがちだ。例えば、夜遊び、お酒、ギャンブルなど。「普通であることの勇気」はケを受け入れろ、と言っているように感じた。
特別である必要はないと言いつつキラキラした言葉を使う
この本は、特別な存在である必要はなく、普通であることの勇気を持とう、という。高邁なる目標をめざすような、人生を「線」と捉える生き方ではなく、人生を点の連続、つまり「いま、ここ」に強烈なスポットライトを当てダンスすように生きようという。
しかし、このダンスやスポットライトなどの言葉はドラマチックでキラキラしていて、「私は特別」という思いが見え隠れする。なぜこんな言葉を使うのか。「いま、ここ」だけでよいのではないか。劇的なイメージは物語を前提にしていて、この本の趣旨と矛盾する。
この本では、高邁な目標などに陶酔してしまい地に足つかない生き方を戒めていると思うのだが、ダンスやスポットライトはまさに陶酔を促す言葉ではないか。
この本から得られること
自分の幼稚な言動や考え方に気づいて修正できる
この本は正直、論理的な構成になってないし、矛盾していると思われることも多い。なので、何か一貫性のある主張をしているのかよくわからない。じゃぁ読む価値ないじゃん、って話になるかもしれない。でも読む価値はある。
大人ってこんな人だよなー、とか、しっかりした人ってこんな人だよなー、というざっくりとした人物像を誰しも持っていると思う。過去を言い訳にしないよなー、自分の課題と人の課題を混同しないよなー、自慢しないよなー、不幸自慢もしないよなー、とかって、この本を読むまでもなく、しっかりした人物のイメージとしてあると思う。そういう人物像の具体的な特徴を列挙して記載したのがこの本だと思った。
この本に書いてあることが頭に入っていると、自分を含めて人の幼稚な言動に気付けて、しかもその言動がなぜ幼稚なのかがわかる。ただ、そのような言動をなくせるかどうかは別問題だ。正直、非常に厳しいことが書いてある。理想主義的とさえ言える。でも、気付くことが修正の第一歩になる。
現代社会を生きるために染まった考えを中和する効果
競争社会や市場社会では、他人と比較したり他者からの評価を気にして苦しんでいる人が多いのではないか。また、就活市場、恋愛・婚活市場・SNSでは自分に物語を付与してセルフブランディングをするのが普通だが、そんな物語に縛られて苦しんでいる人も多いだろう。
そういった現代に最適化して苦しんでいる人への中和剤になる考え方がこの本には書かれている。承認欲求、他者との比較、物語を否定する。
とはいえ、そうした現代に最適化した考え方というのは必要だから身につけたスキルのようなものだ。今更、そういう考え方を完全に捨ててしまえば競争社会や市場社会では生き残れないのが現実だろう。なので、あくまで「中和剤」だ。この本のような逆の考え方を知ることで、苦しくならない程度に両者の間でバランスをとって生きていける。
さいごに
私は最近Takerに遭遇してしまう機会が多く、どのように考えたり、対処していけばいいかのヒントを得るためにこの本を学び直しました。その具体的な答えは正直みつかりませんでした。ただ、やはり課題の分離や、存在のレベルでの感謝などが鍵になるように感じました。後は実際の生活のなかから自分で掴み取っていくしかないのだと思います。
正直、マニュアル的に手取り足とり細かく書かれたノウハウを求めている人にはオススメできません。細かく見ていくと矛盾点がたくさんみつかり混乱して実践できないでしょう。
ただ、おおまかな大人な個人としての考え方や振る舞いの方向性が知れて、現代の競争社会に最適化した考えを中和する効果があり、それを自分の生活の中で応用して自分なりのノウハウを見つけられる人には良い本かもしれません。
The post "嫌われる勇気"の要約と感想!大量の矛盾点との向き合い方 first appeared on WebFood.
]]>The post WebArena Indigoの評判!激安だけど停止中も課金はズルい first appeared on WebFood.
]]>WebArena Indigoを使ってみました。ネット上に口コミが少なかったので、体験レビューをお伝えします。
検索順位チェック用のサーバーのため
ブログのSEO対策のため、自動でGoogleでの検索順位をチェックするためにGRCというツールを使っているのですが、サーバー側で利用できるSERPOSCOPEというオープンソースに切り替えることにしました。その際にSERPOSCOPEはJavaで書かれています。ロリポップなどの格安のレンタルサーバーなどはJavaには対応していないので、VPSを使う必要が出てきました。
WordPressのように一般のユーザが使うための用途ではなく、使うのはこちら側の人間だけなので、スペックは最低限で良いと考えました。
最安値で探したところWebArena Indigoが見つかりました。月に349円で使えます。その割にNTTグループで、多少信頼感があります。
さっそく申し込む
各プランのところに申し込みボタンがありますが、どのボタンを押しても同じっぽいです。
個人情報を入力していきます。
メールアドレス宛に送られたリンクをクリックします。
電話番号の確認が求められます。
カード情報を入力します。Kyashというプリペイドタイプのカードだと不可だったので、通常のクレジットカードで登録しました。
管理画面が2段階になっていて、まずWebArenaの管理画面が表示されます。下のボタンをクリックすると、Indigoの管理画面が表示されます。
インスタンスを作成する
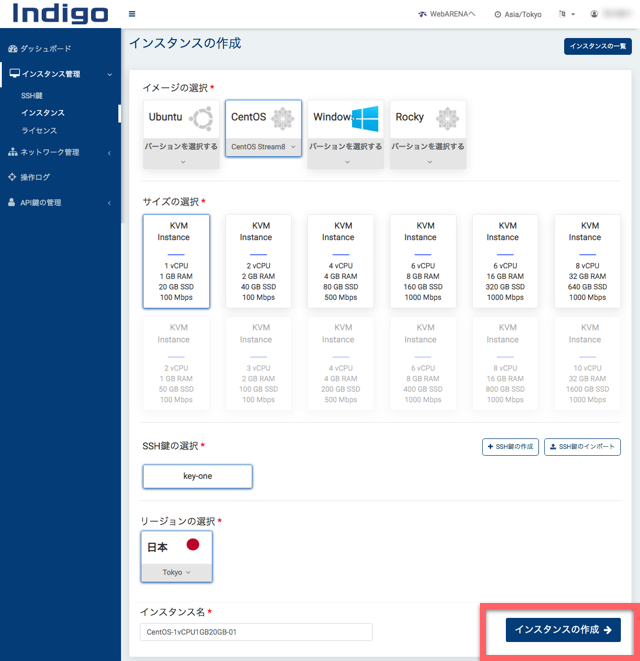
Indigoの管理画面が表示されたら、インスタンスを作成します。
イメージはCentOS Stream8を選びます。競合サービスのConoha VPSは、WordPress用イメージ、MineCraft用イメージなど、用途によってセットアップ済みのイメージが複数あるのですが、IndigoはまっさらなOSのイメージしかありません。なので、あとで色々なソフトウェアを自分でインストール、設定する必要があります。
サイズは最低スペックの1vCPUのものを選択します。
そして、「SSH鍵の作成」をクリックします。
SSH鍵の名前を決めます。「作成」をクリックすると自動的に秘密鍵が記述されたファイルがダウンロードされます。これはなくさないように保存します。
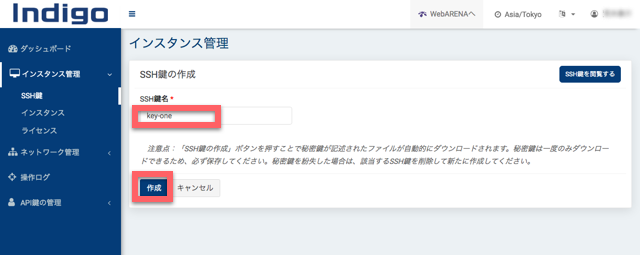
「インスタンスの作成」をクリックします。
インスタンスが作られます。管理画面はシンプルで見やすいですね。
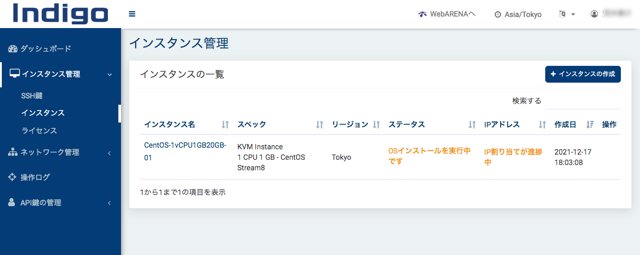
数分すると、IPアドレスが表示され、ステータスが「Stopped」となります。ここで、「操作」から「インスタンスの起動」をクリックします。
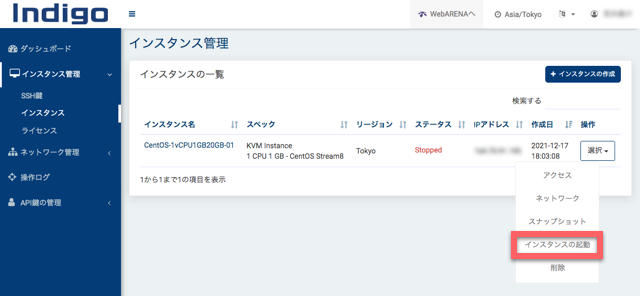
数分するとステータスが「Running」となります。これでVPSの作成は完了です。ターミナルからsshで作業するためにIPアドレスが必要になるのでメモしておきます。
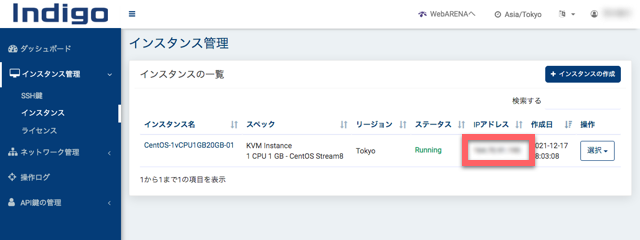
申込開始からここまで、少し迷いながらやって20分程度かかりました。
スポンサーリンク
ターミナルから設定作業をする
Macならターミナル.app、WindowsならTeraTermなどのコンソールからVPSにsshでアクセスして設定作業を行います。
先ほどダウンロードした秘密鍵があるディレクトリに移動し、以下のようにしてsshでアクセスします。-iで秘密鍵を指定します。「**.**.**.**」は先ほどメモしたIPアドレスです。
$ ssh -i private_key.txt centos@**.**.**.**
この時、以下のようなエラーが発生し、ログインできない場合があります。
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ Permissions 0644 for 'private_key.txt' are too open. It is required that your private key files are NOT accessible by others. This private key will be ignored. Load key "private_key.txt": bad permissions centos@**.**.**.**: Permission denied (publickey,gssapi-keyex,gssapi-with-mic).
秘密鍵のパーミッションが広すぎるということです。なので以下のコマンドで制限します。
$ chmod 400 private_key.txt
この後に、もう一度sshするコマンドを実行すればログインできるはずです。
実は、管理画面から直接的にWEBのコンソールを開く機能があるのですが、まず上記のようにターミナルからsshログインしてからパスワードを設定してからでないと使えません。このあたり、ターミナル作業をしたことがない方は少し抵抗があるかもしれません。
ここから、以下の記事の通りSERPOSCOPEを設定して問題なく使うことができました。
[card name=serposcope-review]
インスタンス停止中も課金される
よく考えたら、検索順位チェックのためのサーバーなので、一般のユーザーが使うわけではないので常に起動しておく必要はないと気づきました。
もしかしたら、普段はインスタンスを停止中にしておいて、使う時だけ起動したらかなり安上がりになるのではないか?と考えました。しかし、調べてみるとそういうわけにはいかないことがわかりました。課金を停止するには、インスタンスを「削除」する必要があります。
インスタンスの料金は、インスタンスを作成した時点から廃棄までの間に発生します。停止中のインスタンスにも料金は発生します。
本場アメリカのクラウドサービスであるAWSなんかはEC2というVPSは停止中は課金されません。(とはいえEBSというディスク部分は停止中も課金されるのである程度はお金かかります)
調べてみると日本のサービスのConoha VPSはIndigoと同じく停止中も課金されてしまいます。なので、日本のこの手のサービスは基本料金が安いかわりに、停止中も課金するということで売上をキープする戦術なのだと思います。
技術がある方は、EC2などで細かく起動、停止したり、CRON実行前に起動、CRON終了後に停止などのプログラミングをしたりして、もっと安く運用できるかもしれません。でも、月に数百円のためにそこまで複雑な仕組みを運用する必要もないと思います。
まとめ
WebArena Indigoの良い点と悪い点をまとめます。
- とにかく安い
- NTTグループが運営しているので安心感がある
- 20分でインスタンス作成完了
- 管理画面がシンプルで見やすい
- 電話番号の認証が必要
- 各用途向けにセットアップされたイメージが無い
- コンソールでの作業が必須
- インスタンス停止中も課金されてしまう
セットアップ済みのイメージがないし、ターミナル作業が必須なので、技術に全く自信がない方にはオススメしません。
でも、ある程度自信ややる気がある方にとっては、シンプルで無駄が無く使いやすい上に、激安で使える良いサービスですね。
The post WebArena Indigoの評判!激安だけど停止中も課金はズルい first appeared on WebFood.
]]>The post GRCよりいい?SERPOSCOPEの評判と使い方!使えないなんて嘘! first appeared on WebFood.
]]>GRCの使いづらさにうんざりしてきたので、SERPOSCOPEに乗り換えました。使い方と使ってみた感想をお伝えします。
2022年6月のGoogleの仕様変更により、私のスキルではSERPOSCOPEを運用することができない状況です。詳しくは目次から「またGoogleの仕様変更でエラー発生」のセクションをご覧下さい。ちなみに、次の記事にあるように今はWineというツールでMacでGRCを動かす方法に移行しています。
[card name=wine-grc]
GRCの起動が面倒で半年以上順位チェックしなかった
GRCでチェックするには基本的にパソコンを起動する必要があります。キーワード数が多くなると数時間それにかかり、その間パソコンをシャットダウンできません。
パソコンを起動したくない日だってありますよね。GRCのためにパソコンを起動するなんて、なんだかコンピューターの奴隷になった気分になります。本来は人間が主人でコンピューターが奴隷であるべきです。
さらに、GRCはWindows専用です。以下で書いたように私はMacを使っているので、Prallels Desktopという特殊なソフトを使ってMac上にWindowsを起動しGRCを動かさなくてはいけません。非常に面倒くさいです。また、GRCだけのために Windowsを動かしているので、チェック中はとても負荷が大きくなり、Macのファンがうるさくなります。
[card name=bootcamp-vs-parallels-11-vs-fusion-8]
そういう気持ちだったので、しだいにGRCでチェックの起動をするのをサボるようになり、半年以上も経ってしまいました。
GRCの料金はえげつない
私は100以上のURLで1000以上のキーワードをチェックしていたので、GRCの「エキスパート」というプランになり、月に1,485円になります。私の携帯代くらいかかってるんですよね。
GRCはチームで共有できない
高い金額を払ってもGRCは基本的に一人しか見ることができません。手元のパソコンにインストールするソフトだからです。
私はサイト運営の仕事をチーム化しようとしています。検索順位についてもチームで管理できた方が良いに決まっています。
もちろんサーバー側のWindowsにGRCをインストールすれば、チームでリモートから使うことができるかもしれません。でもちょっと調べた感じだとWindowsが手軽に使えるサーバー業者って無いし、あっても料金が高いです。
オープンソースのSEPORSCOPEに惹かれる
移行先を考えていましたが、一度知人から噂を聞いていたSERPOSCOPを思い出しました。たしかサーバーで動くオープンソースのソフトウェアです。ということは基本的には無料で使えます。パソコン上で使えば無料で使えますし、サーバーで使っても月数百円で使えそうです。そして、URLもキーワードも数に上限がありません。
RankTrackerなどMacで使える有料ソフトもありましたが、サーバーで動き基本は無料のSERPOSCOPEの方が魅力的だと感じました。
YahooもBingも要らんだろ
しかし、SERPOSCOPEはGoogleにしか対応していません。GRCではGoogleに加えて、YahooとBingの検索結果もチェックします。
しかし、実際の運用ではGoogleだけでいいなと考えていました。
YahooはGoogleのアルゴリズムを採用しているのでほぼ同じだし、Bingは検索市場でのシェアがわずかなのでほとんどアクセスは無いので無視して問題ありません。
そもそも指標というものは少なくてシンプルな方がわかりやすくてモチベーションが上がります。なのでGoogleだけで十分です。
スポンサーリンク
GRCの囲い込み作戦にうんざり
GRCからの移行を考え始めて、これまでのデータはSERPOSCOPEに全て移行できるのだろうかと考えました。
GRCに蓄積した全データを1ファイルに出力する機能があります。そのファイルを「引越しデータファイル」と呼びます。パソコンを買い換える際のために使うためのもののようです。全データを出力する機能はこれしかありません。このデータを出力してみたところ、拡張しが「.dat」というものでした。テキストエディターなどで開くことはできません。
CSVやXMLなどの形式であれば、エディターで開いて、なんとかSERPOSCOPEのデータ形式に変換することも可能でしょう。
しかし、この「引っ越しデータファイル」はまるで他のツールへの移行を邪魔するかのようにdatを採用しています。蓄積されるデータが多くなればなるほど移行が大変になります。
これは囲い込みと思われてもしかたないと思います。普段から「読者のために」と思ってこのブログを運営している私は、「ユーザのために」とは逆行しているGRCの姿勢に違和感を感じ、SERPOSCOPEへの移行の意志を強くしました。最悪、今までのデータはなくなってもいいやと考えました。
共用サーバーではなくVPSが必要と気づく
WordPressなどが使えるロリポップなどの共用サーバーでSERPOSCOPEが使えるのかなと思っていました。そうすると月に330円とかで使えます。私の場合、以下で書いたようにすでにロリポップを使っていたので、そこに相乗りすれば無料で使えるということです。
[card name=muumuu-domain-for-lolipop]
しかし、SERPOSCOPEはPHPではなくJavaで動いていることがわかりました。ということはJavaが動く共用サーバーを探さなければいけません。すると、1stRentalServerというサービスをみつけましたが、料金は月775円からとそこまで安くありません。
そうなるとOSから自由にソフトウェアをインストールできるVPSが必要ということになります。
WordPressを運用しているVPSに相乗りはリスクかも
VPSといえば、当サイトもWordPressを利用し、Conoha VPSというVPSで運用しています。そのVPSにJavaをインストールすれば追加料金ゼロでSERPOSCOPEを使えるじゃん。
しかし、よく考えるとこのアイディアには2つのリスクがあることに気づきました。Conoha VPSではWordPress専用のイメージを使っていて、私がゼロから設定したわけではありません。なので、JavaをインストールしてSERPOSCOPEの設定をした場合、どのようなことがあるかわかりません。サイトが落ちてしまったら大変です。
もう1つのリスクとしては、仮に適切にSERPOSCOPEを設定できて運用できたとしても、Googleからペナルティを受けた場合、サイトの評価に影響する可能性がゼロではない、ということです。 SERPOSCOPEは順位チェクのためにGoogleに対して毎日大量のアクセスを不自然なほどすることになります。すると、IPアドレスをブラックリストに入れられる可能性はあります。WordPressもそのIPアドレスなのですから、サイトのGoogleからの評価に影響しないとは言い切れません。
したがって、SERPOSCOPE専用のVPSが必要になります。専用のVPSに載せておけば、もしブラックリストに入れられれば、また新しいVPSを作ればいいのです。
シンプルで最安値のWebArena IndigoでVPS起動
既に利用経験があるConoha VPSで、新しいVPSを立ち上げてもいいのですが、もっと安いVPSはないかと探しました。サイトを運営するわけではないのでスペックは低くても構いません。なので、とにかく安いのを探しました。Conoha VPSは一番安いタイプで月682円です。
すると、WebArena Indigoが月349円ということがわかりました。
Conoha VPSはWordPressが簡単に設定できたり、複数ドメインを1つのVPSで簡単に運用できたりと色々と気が利いているのに対して、IndigoはOSをインストールしてくれるだけです。その分安いのだと思います。
そもそもConohaにもJavaがセットアップされたイメージは無いので、やることはIndigoの場合と同じです。なので安いIndigoを選ばない手はありません。こうしてWebArena Indigoを使うことに決定しました。
ここからは以下の記事にある手順でWebArena IndigoでVPSを起動した前提で、SERPOSCOPEを設定して使用する手順をご説明します。
[card name=webarena-indigo-review]
ターミナルからSSHでログイン
Macならターミナル.app、WindowsならTeraTermなどのコンソールからVPSにsshでアクセスして設定作業を行います。Indigoの管理画面からダウンロードした秘密鍵があるディレクトリに移動し、以下のようにしてsshでアクセスします。-iで秘密鍵を指定します。「**.**.**.**」は先ほどメモしたIPアドレスです。
$ ssh -i private_key.txt centos@**.**.**.**
この時、以下のようなエラーが発生し、ログインできない場合があります。
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ Permissions 0644 for 'private_key.txt' are too open. It is required that your private key files are NOT accessible by others. This private key will be ignored. Load key "private_key.txt": bad permissions centos@**.**.**.**: Permission denied (publickey,gssapi-keyex,gssapi-with-mic).
秘密鍵のパーミッションが広すぎるということです。なので以下のコマンドで制限します。
$ chmod 400 private_key.txt
この後に、もう一度sshするコマンドを実行すればログインできるはずです。
ルート権限になります。
$ sudo su -
デフォルトだとタイムゾーンが日本になっていない場合があるので以下をします。
# timedatectl set-timezone Asia/Tokyo
これをしないと、SERPOSCOPEで記録されるlogなどの時刻が日本のものではなくなりわかりづらくなってしまいます。
Nginxのインストールと設定
Nginxをインストールします。
# yum -y install nginx
ベーシック認証を利用するために、以下をインストールします。
# yum -y install httpd-tools
ベーシック認証のためのファイルを作成します。
webfoodのところにはあなたが設定したいユーザ名に置き換えてください。password:の後には、あなたが設定したいパスワードを入力して下さい。
# sudo htpasswd -c /etc/nginx/.htpasswd webfood New password: Re-type new password: Adding password for user webfood
Nginxの設定ファイルを編集します。
# vi /etc/nginx/nginx.conf
server{}というセクションを以下に置き換えます。
server {
client_max_body_size 100M;
listen 80 default_server;
listen [::]:80 default_server;
server_name _;
root /var/www/serposcope;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
location / {
auth_basic "Restricted"; # 認証時に表示されるメッセージ
auth_basic_user_file /etc/nginx/.htpasswd; # .htpasswdファイルのパス
root /var/www/serposcope;
proxy_pass http://127.0.0.1:7134;
proxy_set_header X-Forwarded-Host $host;
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
2行目はSERPOSCOPEの画面からファイルをアップロードできるようにするために設定しています。バックアップなどのファイルをリストアする際にアップロードできるようにするためにファイルの最大サイズを100MBに設定しています。デフォルトでは1MBなので、それを超えるファイルをアップロードしようとすると「413 Request Entity Too Large」というエラーが発生してしまいます。
12、13行目でベーシック認証の設定をしています。SERPOSCOPE自体にログイン機能があるので不要といえば不要ですが、SERPOSCOPEのログイン画面すら人に見られたくなかったり、セキュリティをさらに高めるために設定しています。一度ログインすれば基本的に再度認証を求められることはなくわずらわしくないので、設定しておいて損は無いです。
15、16行目でポート番号7134へリダイレクトしています。通常SERPOSCOPEは「http://**.**.**.**:7134」というようにURLの最後に7134というポート番号をつけてアクセスする必要があるのですが、この設定のおかげでシンプルに「http://**.**.**.**」でアクセスできるようになります。
設定を反映するためにNginxを再起動します。
# systemctl restart nginx
サーバーを再起動しても自動的にNginxを起動するために以下をします。
# systemctl enable nginx
スポンサーリンク
SELinuxの設定を変更
SELinuxというOS付属のセキュリティシステムが動いています。デフォルトのままだと先ほど設定したNginxのポート番号7134へのリダイレクトが機能しません。なので、以下を設定します。
# setsebool -P httpd_can_network_relay 1 # semanage port -a -t http_port_t -p tcp 7134
Javaのインストール
以下でJavaをインストールします。
# yum -y install java-1.8.0-openjdk.x86_64
確認します。
# java -version openjdk version "1.8.0_312" OpenJDK Runtime Environment (build 1.8.0_312-b07) OpenJDK 64-Bit Server VM (build 25.312-b07, mixed mode)
SERPOSCOPEの配置と起動
配置するディレクトリを作ります。
# mkdir -p /var/www/serposcope # cd /var/www/serposcope
以下のようにしてSERPOSCOPEのファイルを取得します。
# curl -OL https://serposcope.serphacker.com/download/2.14.0/serposcope-2.14.0.jar
上記のURLには執筆時点でのバージョン番号が含まれています。このURLは公式ページで以下のようにして取得できます。
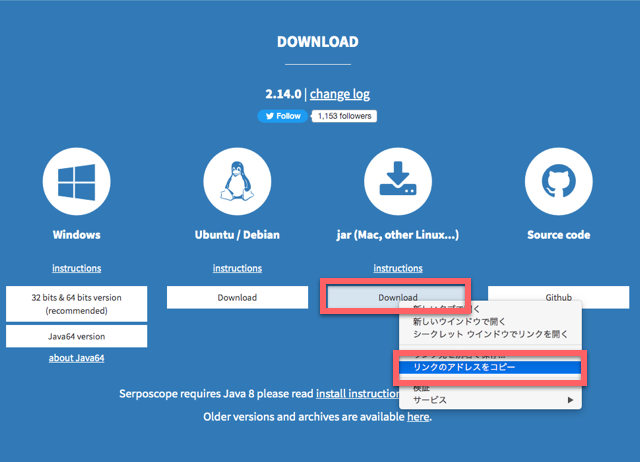
SERPOSCOPEを起動します。nohupと&をつけることでターミナル終了後も動き続けます。
# nohup java -jar /var/www/serposcope/serposcope-2.14.0.jar &
WEBブラウザからアクセス
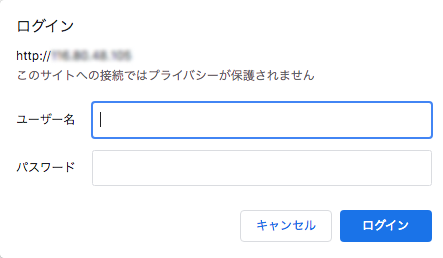
WEBブラウザから「http://**.**.**.**」というURLにアクセスします。「**.**.**.**」はインスタンスのIPアドレスに置き換えます。
すると以下のようなベーシック認証のプロンプトが表示されるので、先ほど設定したユーザ名とパスワードを入力してログインします。
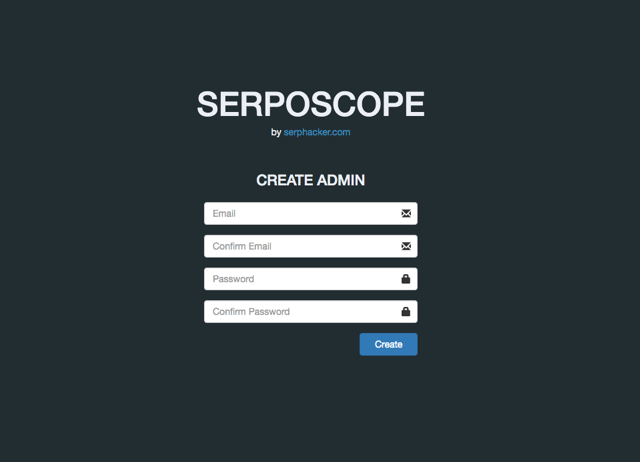
これでSERPOSCOPEの登録画面が表示されます。メールアドレスとパスワードを登録してください。
ログイン画面が表示されるので、今登録したメールアドレスとパスワードでログインします。全て英語の画面になります。
GRCとは違う!「GROUP」という概念
さっそくチェック対象のサイトやキーワードを登録していきます。まず「GROUPS」というメニューを押します。
新しいGROUPを作ります。
GROUPという概念がGRCから移行した方にとっては少しわかりづらいかもしれません。
GRCの「グループ」はあくまで表示だけの問題です。項目をまとめて表示してくれます。各項目は複数のグループに所属できるので、タグ的な使い方ができます。
これに対して、SERPOSCOPEのGROUPは、キーワードとサイトのセットです。あるキーワード群に対して、複数のサイトを順位チェックします。同じキーワード群でチェックしたい複数のサイトがあれば、一つのグループにそれらのサイトを所属させます。すると、一度の処理でそれら複数のサイトの順位を確認することができます。
GRCだと同じキーワードで複数のサイトをチェックしたい場合、それぞれのサイトごとに処理が走ってしまいます。なので、SERPOSCOPEでうまくGROUPを設定すれば、GRCよりも処理が少なくチェックできるということです。
とはいえ、現実的には、同じキーワード群で複数のサイトをチェックしたいケースは少ないと思います。例えば、「脱毛サロン比較サイトA」、「脱毛サロン比較サイトB」のように、ニッチなジャンルで複数のサイトを運営している場合はそのケースにあてはまるでしょう。とはいえ、昨今はそういうゴリゴリのアフィリエイトサイトは少なくなっていると思います。
なので、グループ一つに対して、サイト一つを所属させるという運用になると思います。したがって、私は以下のようにグループ名はサイト名(ドメイン名)にしてしまいます。
次にそのグループにサイトを登録します。
NAMEとPatternにもドメイン名でOKです。
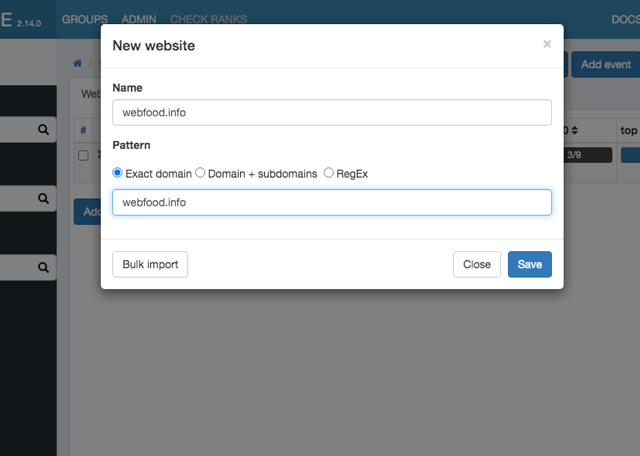
キーワードは一括登録できるけどちょっとトリッキー
サイトを登録したら、キーワードの登録をします。
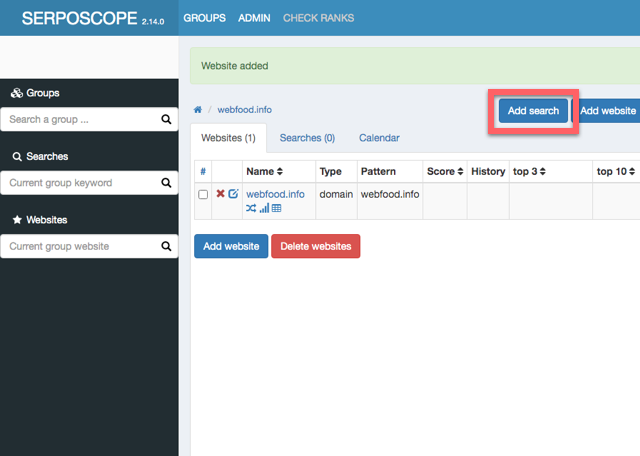
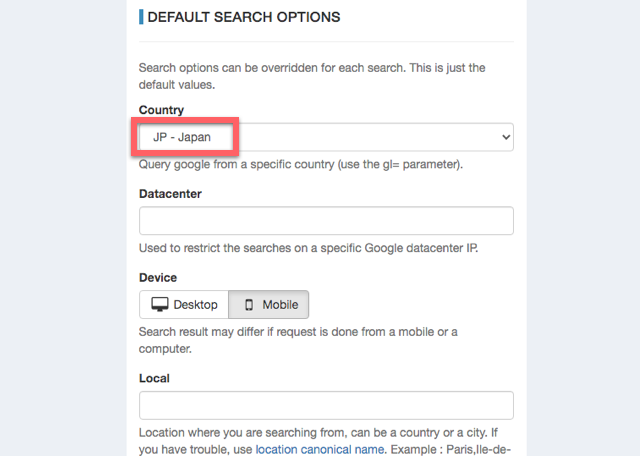
「New Search」の画面で、Keywordを入力したら、Countryには「JP-Japan」、Deviceには「Mobile」を選択してSaveします。基本的に昨今はスマホからのアクセスが主流になっているのでMobileだけチェックすればいいでしょう。これまでの経験上、スマホからの検索順位もパソコンからの検索順位もそこまで変わらないので、どちらでも良いと言えば良いです。両方調べたい場合は、それぞれの分登録します。とはいえ、全キーワードを両方チェックしていたら処理が多くなってしまうので、Mobileだけで十分です。
他の項目は特に何も設定しなくて大丈夫です。
ちなみに、設定画面でCountryのデフォルト値を変えられます。「JP-Japan」にしておくと楽です。ADMINからGOOGLEをクリックします。
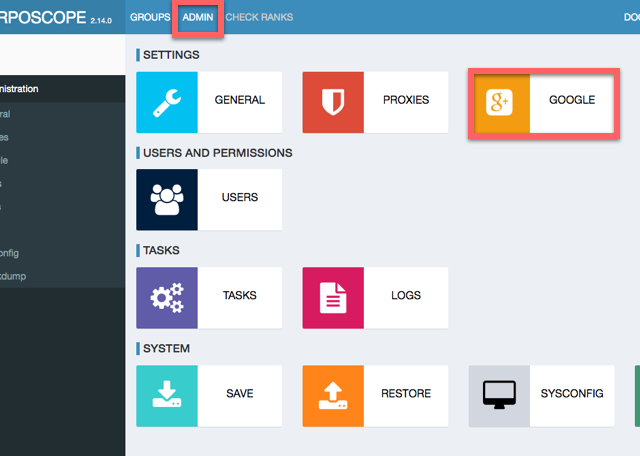
少しスクロールすると、デフォルト値を設定できるフォームがあります。Deviceもあるので設定できるのかと思ったのですが、なぜかここでMobileにしても反映されませんでした。多分バグでしょう。
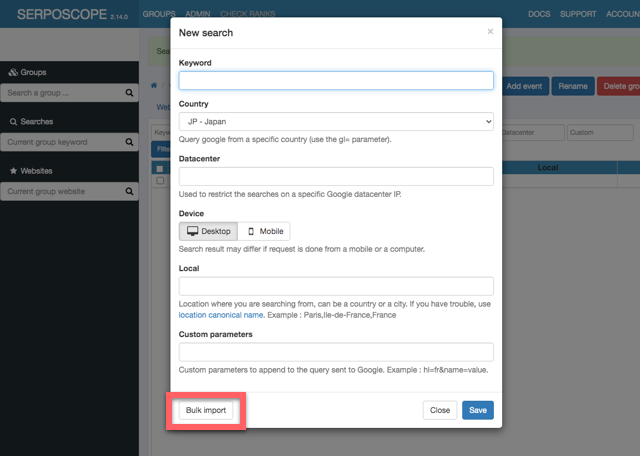
キーワードは複数を一括登録することもできます。先ほどの「New Search」の画面で、「Bulk Import」を押します。
すると複数行入力できるフォームが現れるので、1行に1キーワードを入力します。ただ、Countryをはじめとする他の項目も入力する必要があり、カンマ区切りで入力する必要があります。
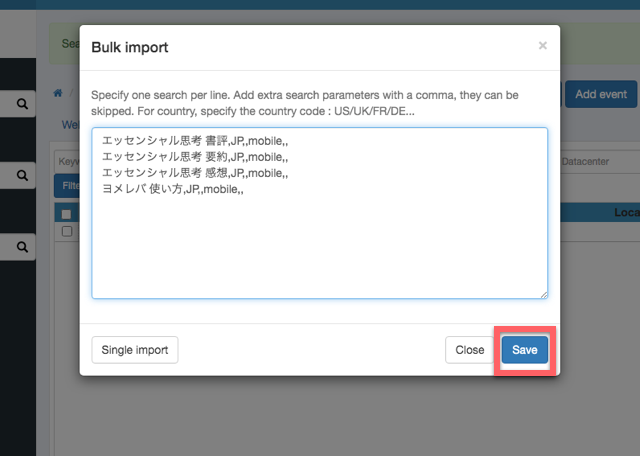
keyword,country-code,datacenter,device,local,custom
という順番です。必要なのは、keyword、country-code、deviceです。なので、例えば、「エッセンシャル思考 書評」というキーワードなら、
エッセンシャル思考 書評,JP,,mobile,,
と入力します。残念ながらデフォルト値にJPと設定していても、ここでは指定する必要があります。これを1行に1キーワード分を入力します。例えば4つのキーワードなら以下のように入力します。
エッセンシャル思考 書評,JP,,mobile,,
エッセンシャル思考 要約,JP,,mobile,,
エッセンシャル思考 感想,JP,,mobile,,
ヨメレバ 使い方,JP,,mobile,,
キーワードが数十個など多くなってくると、1行1行を手作業で作ると大変です。なので、正規表現が使えるエディターなどを使って、キーワードだけの一覧に、残りの文字列を一括で付与するといいでしょう。例えば、上記は元々は以下のキーワードだけの一覧でした。
エッセンシャル思考 書評
エッセンシャル思考 要約
エッセンシャル思考 感想
ヨメレバ 使い方
私はAtomというエディターを使っています。正規表現を有効にして置換します。置換対象として以下を指定します。これは改行コードを表す正規表現です。
\n
置換後の文字列を以下とします。改行コードの前に、他の項目を示すカンマ区切りの文字列を指定しています。
,JP,,mobile,,\n
これで一括置換すると、一瞬で先ほどの形式になります。この辺りは人それぞれ楽な方法があると思いますので、一例としてやり方を説明しました。
キーワードが登録できたら、さっそく順位チェックの処理を走らせます。
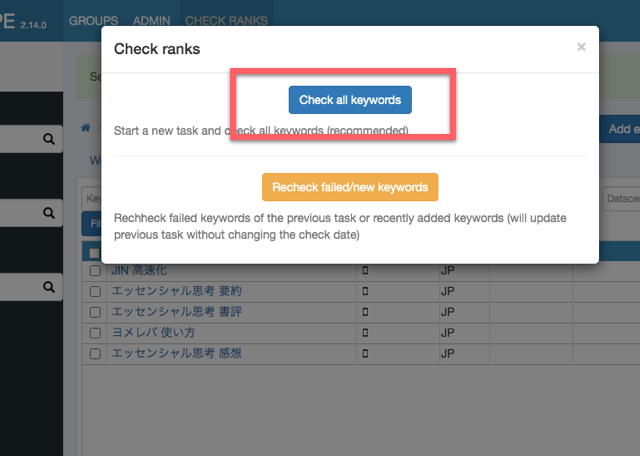
メーターが表示されるので、100%になったら完了です。
初回でたまたまチェック処理が成功することもあります。しかし、このままだと、多くの場合はエラーが発生すると思ってください。エラーへの対策は後述します。
チェック処理のスピードは厳密に比べてはいないのですが、GRCと比べて遅いということはないです。私の場合、初期設定のままで954キーワードで64分かかっています。ざっくり1000キーワードで1時間ということです。
順位を確認するには、サイトごとの画面まで行く必要があります。まずGROUPSを押します。
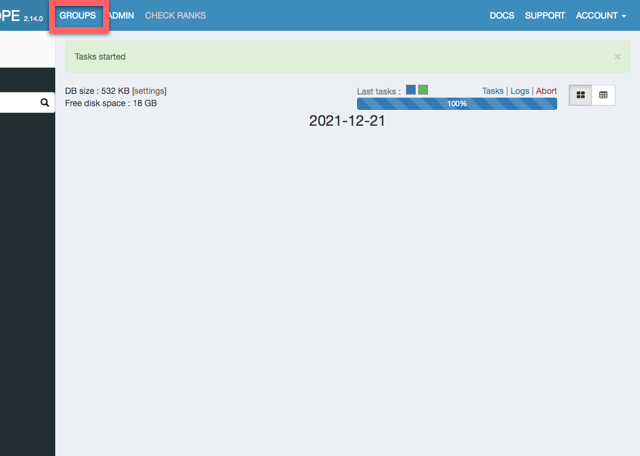
グループ名を押します。
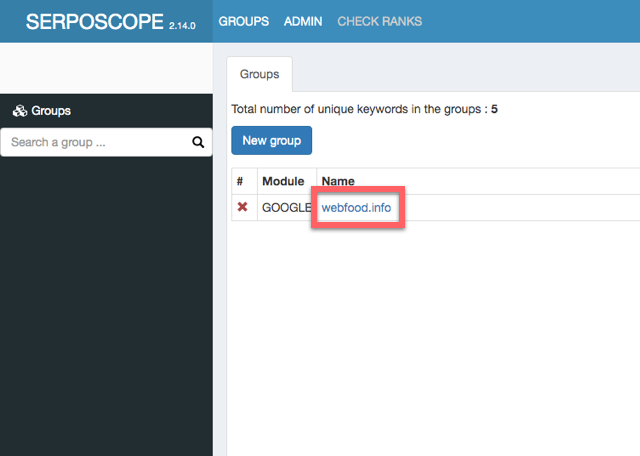
サイト名を押します。
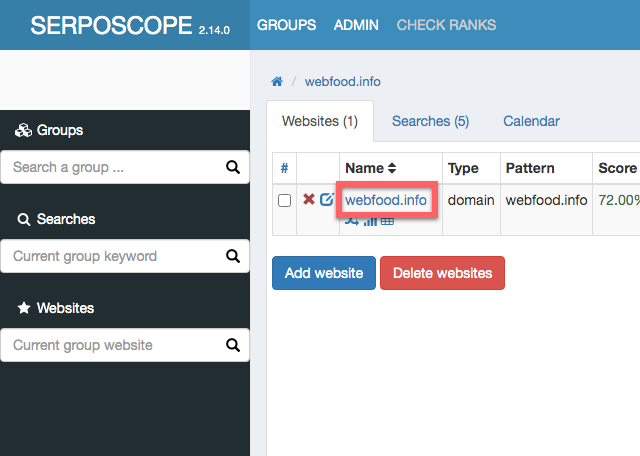
すると順位が表示されます。
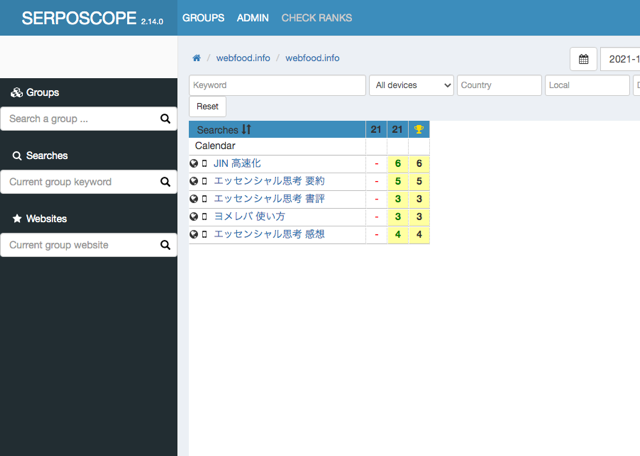
スポンサーリンク
毎日特定の時間に自動的に一括チェックできる
SERPOSCOPEはわざわざ手動でチェック処理を起動しなくても、毎日特定の時間に自動的にチェック処理をしてくれるように設定できます。GRCでもできましたが、SERPOSCOPEはサーバー側にあるので、パソコンを開いていなくてもチェックしてくれます。
ADMINからGENERALを開きます。
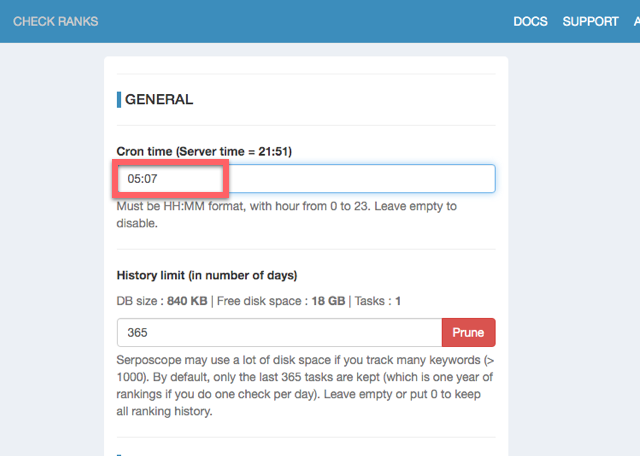
Cron Timeに、毎日自動的にチェックしてほしい時間を入力してSaveします。私の場合は、朝方の私が作業していない時間に走らせるようにしています。5時丁度などはGoogleさんに怪しまれそうなので、少し中途半端な時間にしています。
絶対に起こるチェック処理でのエラー
チェック処理を走らせると間違いなくエラーが発生すると思ってください。以下のように「Failure」と表示されます。Logsを押すとエラーの内容を確認できます。
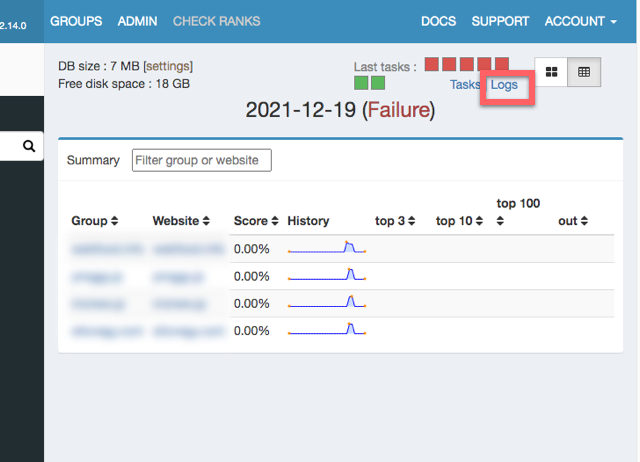
ログのエラーの周辺部分を切り出しました。
[2021-12-16 17:09:28,760] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-104#&gl=jp&num=100 via proxy:direct try 1 [2021-12-16 17:09:29,181] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[302] exception=[none] [2021-12-16 17:09:29,714] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT[refetch] status=[302] exception=[none] [2021-12-16 17:09:29,715] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - captcha form detected via proxy:direct [2021-12-16 17:09:29,762] [google-0] WARN c.s.s.t.g.GoogleTaskRunnable - scrap failed for #OBF#search-104# because of ERROR_CAPTCHA_NO_SOLVER
5行目の「ERROR_CAPTCHA_NO_SOLVER」というのがエラーの種類を表しています。結論からいうと、このエラーは解決可能です。
ANTI CAPTCHAでこのエラーは解消
ERROR_CAPTCHA_NO_SOLVERというエラーについて説明します。最近のWebサービスでは、人間とSERPOSCOPEのようなボットを区別するためにCAPTCHAという仕組みがあります。これは手書きの文字の画像を読ませて入力させたり、特定の種類の写真を選ばせたりします。人間と判断できれば、正常に使用させてくれますが、ボットだと判断されればエラーを表示しそれ以上の利用を拒否します。Googleも怪しいアクセスには、検索結果を返さずCAPTCHAを表示します。AIなどの技術を使ってもボットはこれをクリアできません。
しかし、最近ではこのCAPTCHAを乗り越える仕組みが出来てきています。どのような仕組みかというと、AIではなく「人間」を使います。ボットに対してCAPTCHAが表示された時に、即座に世界中に待機している人間の誰かに自動的に割り振ります。その人がそのCAPTCHAを解きます。すると、WEBサービスはそのボットを人間とみなしてくれます。
おそらく、そのCAPTCHAを解いてくれる人は、発展途上国に住む方々だと思われます。解くごとにわずかばかりのお金が彼らに支払われます。先進国に住む人にとっては少額でも、物価の安い発展途上国の人にとってみれば良い仕事になっているのでしょう。なので、そのような仕組みを使うボットを運営する側の人がお金を払うことになります。とはいえ、あとで説明しますが、SERPOSCOPEの場合、非常に少額で無視レベルできるのコストです。
そのようなCAPTCHAを乗り越える仕組みの一つがANTI CAPTCHAというサービスです。日本人スタッフがいないのか、日本語が少しおかしい部分がありますが、それはご愛嬌(笑)
このサービスでアカウントを作って入金します。
メールアドレスに送られてきたパスワードを使ってログインします。ログインすると利用規約が表示されます。
入金します。前払いである程度のデポジットをしておき、CAPTCHAを解決してもらうごとにそこから引かれるという仕組みです。
様々な支払い手段がありますが、私の場合はVISAで行いました。

この支払い方法の選択の意味がよくわからなかったのですが、とりあえず「クレジットまたはデビットカードでのお支払い」を選択しました。
最少額の5ドルを選択します。
カード情報を入力します。
ちなみにKyashなどのプリペイド型のカード情報だとうまくいかないようです。通常のクレジットカードの情報を入力します。

一人一人に割り振られる、アカウントキーをコピーします。
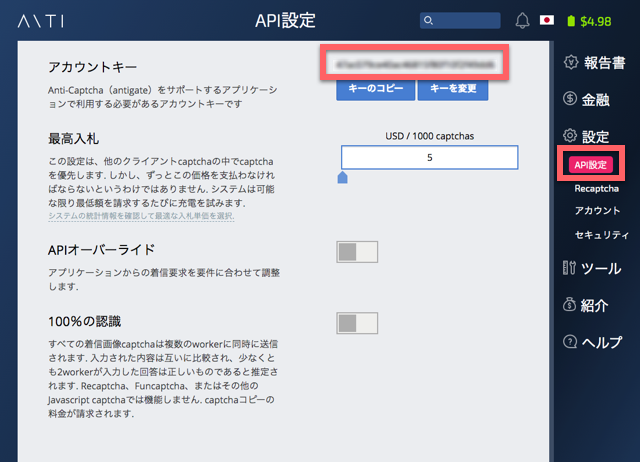
これをSERPOSCOPE側の設定画面で入力します。どこに入力するかというと、ADMINからGENERALを開きます。

少しスクロールすると、ANTI CAPTCHA用の入力欄があります。ここに先ほどのキーを入力し、「Test credentials」を押して問題なければSaveします。これでERROR_CAPTCHA_NO_SOLVERは発生しなくなります。
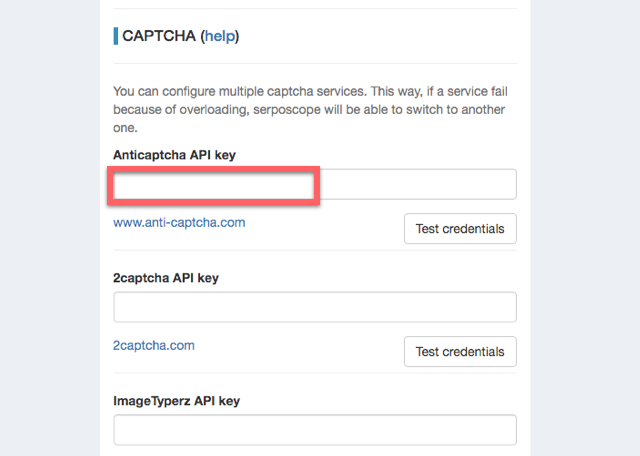
ちなみに、同様の他のサービス用の入力欄もあります。複数のサービスを設定しておくと、一つのサービスで解決してくれる人がすぐに応募してくれない場合、他のサービスに切り替わり、解決できないという可能性をさらに下げることができます。とはいえ、私の場合はANTI CAPTCHAだけでも問題は発生していません。
ANTI CAPTCHAにどのくらいコストがかかるのか気になると思いますが、思った以上に少ないです。ANTI CAPTCHAの管理画面で、利用実績を確認できます。
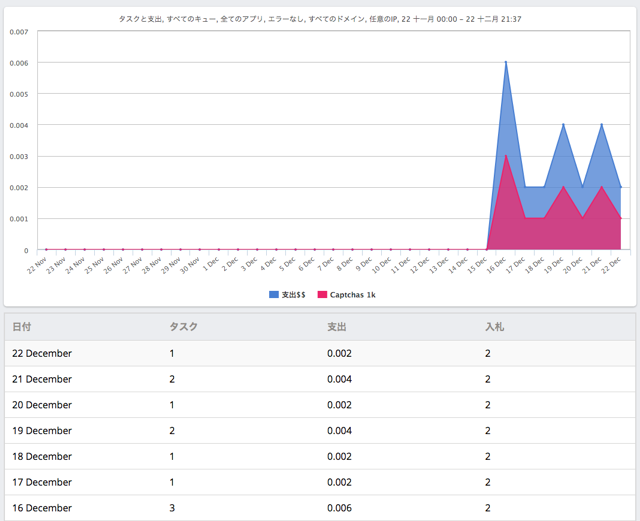
なんと1日1回〜3回程度しか利用されておらず、金額にすると0.002〜0.006ドルしか使われていません。私はこの時点で954キーワードありますが、キーワードごとにCAPTCHAが発生するわけではなく、1日に1回〜3回程度発生してそれを解決すれば他のキーワードでは発生していないということです。
1週間使いましたが0.02ドルしか使われていません。なので、1ヶ月使っても0.08ドルということです。大体9円程度です。
つまり、954キーワードでも1月9円ということです。なので無視できるレベルのコストと言っていいでしょう。
おそらく、キーワードの数に比例してコストが増えるわけではないです。基本的に何キーワードあっても一括処理は1日1回です。そのたびに1〜3回程度CAPTCHAが発生するだけだからです。
CAPTCHAの問題はGRCでも発生しているはずです。GRCでも裏ではこういうサービスを使って対処しているのでしょう。
ERROR_NETWORKはやっかいかも
実は最初に作ったWebArena Indigoで最初に作ったVPSでチェック処理を走らせた際に、Failureとなりました。その時のログからエラー周辺を切り出したものです。
[2021-12-18 03:06:08,474] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-309#&gl=jp&num=100 via proxy:direct try 1 [2021-12-18 03:06:08,617] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[302] exception=[none] [2021-12-18 03:06:08,675] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT[refetch] status=[302] exception=[none] [2021-12-18 03:06:08,675] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-309#&gl=jp&num=100 via proxy:direct try 2 [2021-12-18 03:06:08,841] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[302] exception=[none] [2021-12-18 03:06:08,884] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT[refetch] status=[302] exception=[none] [2021-12-18 03:06:08,884] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-309#&gl=jp&num=100 via proxy:direct try 3 [2021-12-18 03:06:09,054] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[302] exception=[none] [2021-12-18 03:06:09,099] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT[refetch] status=[302] exception=[none] [2021-12-18 03:06:09,107] [google-0] WARN c.s.s.t.g.GoogleTaskRunnable - scrap failed for #OBF#search-309# because of ERROR_NETWORK [2021-12-18 03:06:09,108] [google-0] WARN c.s.s.t.g.GoogleTaskRunnable - no more proxy, stopping the thread [2021-12-18 03:06:09,108] [google-0] INFO c.s.s.t.g.GoogleTaskRunnable - google thread stopped [2021-12-18 03:06:09,143] [Thread-13] WARN c.s.s.t.g.GoogleTask - 1 proxies failed during the task
10行目に「ERROR_NETWORK」とあります。ネットで調べると、設定画面で変更できるGoogleへのアクセスの間隔(Pause)です。キーワードごとにGoogleへアクセスしますが、その間隔の時間を長くとることでこのエラーはなくなる、という情報がありました。
最初に何キーワードかは成功していて、途中でこのエラーが発生している場合は、もしかしたらPauseの値を調整することでエラーが発生しなくなるかもしれません。
しかし、私の場合は、1キーワード目でこのエラーが発生します。何回処理をやり直しても1キーワード目で発生します。なので、Pauseは関係ありません。
数時間試行錯誤した末、よくわからなかったので、IndigoでVPSをゼロから作成しなおして、再度SERPOSCOPEをセットアップして処理を実行したら、なぜかこのエラーは発生しなくなりました。
もしかしたら、何らかの理由で一度Googleにボット認定されたらIPアドレスがブラックリストに載ってしまうのかもしれません。なのでVPSを作り直してIPアドレスが変わった途端、エラーが無くなったのかもしれません。
VPSは簡単に作り直せて手軽にIPアドレスを変えられるので、SERPOSCOPEと相性がいいですね。ちなみに、GRCなどで手元の端末から順位チェックしていてブラックリストに入れられてしまった場合は大変です。オフィスや自宅やモバイルWifiのIPアドレスがブラックリストに入れられたことになります。それらのIPアドレスは簡単には変えられません。
Googleの仕様変更で処理が落ちてもすぐに対応
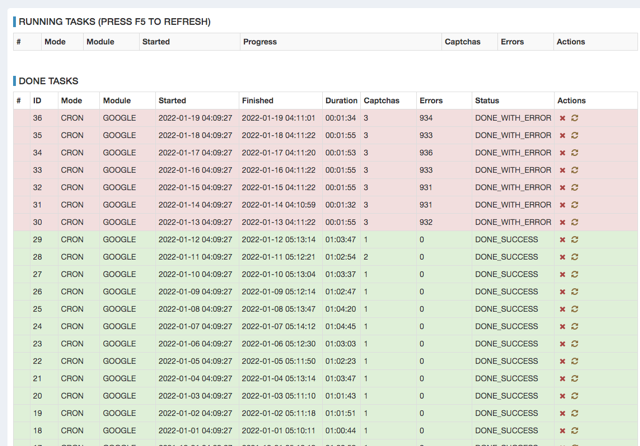
ある日数日ぶりにSERPOSCOPEにブラウザからアクセスしてみると、Failureという赤文字が表示されました。Tasksの画面を開くと、6日前からタスクが落ちていることがわかりました。
ログを開いてみると、
[2022-01-19 04:11:00,151] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-643#&gl=jp&num=100 via proxy:direct try 1 [2022-01-19 04:11:00,541] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[302] exception=[none] [2022-01-19 04:11:00,975] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT[refetch] status=[302] exception=[none] [2022-01-19 04:11:00,975] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - captcha form detected via proxy:direct [2022-01-19 04:11:01,010] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - noscript form detected, trying with captcha image [2022-01-19 04:11:01,010] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - can't find captcha img tag [2022-01-19 04:11:01,010] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-643#&gl=jp&num=100 via proxy:direct try 2 [2022-01-19 04:11:01,404] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[302] exception=[none] [2022-01-19 04:11:01,656] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT[refetch] status=[302] exception=[none] [2022-01-19 04:11:01,656] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - captcha form detected via proxy:direct [2022-01-19 04:11:01,692] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - noscript form detected, trying with captcha image [2022-01-19 04:11:01,693] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - can't find captcha img tag [2022-01-19 04:11:01,693] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-643#&gl=jp&num=100 via proxy:direct try 3 [2022-01-19 04:11:02,235] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[302] exception=[none] [2022-01-19 04:11:02,562] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT[refetch] status=[302] exception=[none] [2022-01-19 04:11:02,562] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - captcha form detected via proxy:direct [2022-01-19 04:11:02,598] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - noscript form detected, trying with captcha image [2022-01-19 04:11:02,598] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - can't find captcha img tag [2022-01-19 04:11:02,598] [google-0] WARN c.s.s.t.g.GoogleTaskRunnable - scrap failed for #OBF#search-643# because of ERROR_NETWORK [2022-01-19 04:11:02,598] [google-0] WARN c.s.s.t.g.GoogleTaskRunnable - no more proxy, stopping the thread [2022-01-19 04:11:02,598] [google-0] INFO c.s.s.t.g.GoogleTaskRunnable - google thread stopped [2022-01-19 04:11:02,601] [Thread-43] WARN c.s.s.t.g.GoogleTask - 1 proxies failed during the task
5、6行目のようなメッセージが出て、「can't find captcha img tag」となっていました。19行目で「ERROR_NETWORK」となり処理が終了していました。
とりあえず、他の人も同じような事象を経験していないかフォーラムを調べてみました。
すると、以下のように全く同じ事象を報告するスレッドがあり、読んで行くと開発側がすぐに対応して最新版で修正すると書いてありました。
Problems with solving captchas
おそらくGoogle側でなんらかの変更があったと思われます。なので、一斉にみなさんエラーが出てここで報告されて、開発側が対処したということです。
この辺りは対応が早いですね。
SERPOSCOPEの画面をよくみると、上のほうにいつもは無い「NEW VERSION!」という文字が表示されていました。
おそらく最新版にUPGRADEすれば直るだろうと考えました。
ただ、6日間気がつかなかったので、処理が落ちたらメールなどで通知してくれる仕組みがあればもっと早く気付くのになと思います。まぁ、ログを解析して落ちてたらメール通知するシェルスクリプトを自分で書いてCronに登録しておけば、同じことができそうですが。
最新版へのUPGRADE方法
公式ドキュメントにUPGRADE方法はサラッとしか書いてありません。
How to upgrade serposcope ?
Before any upgarde, backup your database using the backup feature of the admin panel or by copying the data directory (see below).
Then just install over previous serposcope install.
データのバックアップをとって、前バージョンに新バージョンを上書けと書いてあります。
データのバックアップはとってもいいのですが、明確にデータのディレクトリが決まっているので、UPGRADEの作業で壊れることはないと思うので、特にとりませんでした。
心配であれば、設定画面の「SAVE」でSQLダンプのファイルをダウンロードしておいてもいいかもしれません。
VPSにターミナルからSSHでログインしてUPGRADEの作業をします。
$ ssh -i private_key.txt centos@**.**.**.** $ sudo su - # cd /var/www/serposcope
以下のようにしてSERPOSCOPEの最新のファイルを取得します。指定するURLは前述したインストール時と同じように、公式ページから取得できます。この処理は数分かかります。
# curl -OL https://serposcope.serphacker.com/download/2.15.0/serposcope-2.15.0.jar
現在動いているプロセスの番号を調べて、落とします。
# ps -ef | grep java root 16158 1 0 2021 ? 01:55:43 java -jar /var/www/serposcope/serposcope-2.14.0.jar root 99789 99700 0 16:29 pts/0 00:00:00 grep --color=auto java # kill -9 16158
この段階でブラウザでアクセスしてみると、Nginxの404エラーが出て落ちていることがわかります。
新しい方のファイル名を指定して起動します。
# nohup java -jar /var/www/serposcope/serposcope-2.15.0.jar &
ここで古い方のファイルは削除しても大丈夫ですが、念のため何かあった時に切り戻すために次のUPGRADE時まで残しておいてもいいかもしれません。
これでブラウザからアクセスするとSERPOSCOPEのログイン画面が出るので、ログインするとバージョン番号が最新になっていることが確認できます。
GRCでもおそらく同じようにUPGRADEしなければならない機会はあるはずですが、GRCはクリック1つでUPGRADEできるのであまり意識することはありませんでした。その点SERPOSCOPのUPGRADE作業は少し手数が多いですね。
UPGRADEが完了したので、手動でチェック処理を走らせると問題なく完了しました。
スポンサーリンク
データ量が多くなりそう
少し運用していて気づいたのですが、キーワード一つ一つについて、自分のサイト以外のURLも表示してくれます。ということは、これらのURLも全て毎回保存しているというこです。GRCはこのような機能はデフォルトでは無かったと思います。なので、SERPOSCOPEではデータ量が多くなることが少し心配です。
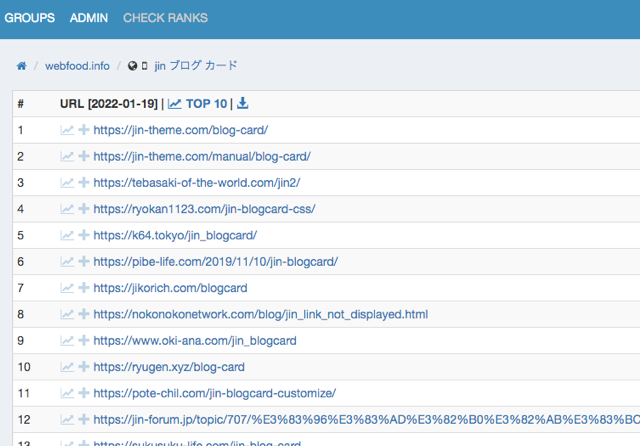
気になったので、SERPOSCOPEのデータが保存されるdb.mv.dbというファイルを調べてみたところ、約340MBになっていました。
約1,000キーワードで1か月使った状態です。ということは1年使うと4GB程度になります。私のVPSは20GBの容量ですが、現在使用可能なのが17GBなので4年程度使えることになります。まぁ、4年使えればいいかなと思いますが、GRCでは容量について意識もしなかったので、少しストレスかもしれません。
設定画面で「History limit」という項目があり、データを何日残すかを決められます。ここでVPSの容量を超えない日数にすればいいと思います。デフォルトは365日になっていてちょっと短いので、伸ばしてもいいかもしれません。
個人的には人のサイトのURLまでは保存しなくてよくて、順位だけ保存してくれれば十分なのになぁと思います。このあたりは変えて欲しいですね。
あと、自動チェックは毎日動く仕様になっているのですが、1週間に1回とかでも良いしその方がデータ量を抑えられると思います。頻度を設定で変更できないのが残念です。
スマホで手軽に確認できる
ブラウザから使えるので、当然スマホからも確認できます。なので電車で移動中にちょろっと見ることだって可能です。処理が落ちた時にメール通知が無いという不満をもらしましたが、毎日のようにスマホでチェックしていれば、処理が落ちていてもすぐに気が付けるかもしれません。
ただ、PC用の画面になっているので、スマホだと少し見づらいです。表が横長なので、左にある肝心のキーワードを見るためには、左まで横スクロールしなければなりません。
画面を横にすると、少し見やすくなりますが、やはりキーワードは左に横スクロールする必要があります。
普通のWEBサイトと同じようにブックマークできるので、iPhoneならホーム画面に入れてワンタップで開くことができます。まるでGRCをスマホにインストールしているかのような感覚です。
ちなみに、iPhoneのSafariだと、なぜかベーシック認証を毎回求められてしまうので、以下の方法でパスワードを保存しておくのがおすすめです。
謎の502エラーで手動でやり直しするハメに
SERPOSCOPE運用開始から50日目くらいに、Failureという赤い文字が表示されていて、その日の自動チェック処理が落ちていることに気づきました。
[2022-02-03 04:38:13,668] [google-0] INFO c.s.s.t.g.GoogleTaskRunnable - search "#OBF#search-757#" | try 1 | total search done : 442/969 [2022-02-03 04:38:13,668] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-757#&gl=jp&num=100 via proxy:direct try 1 [2022-02-03 04:38:15,239] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[502] exception=[none] [2022-02-03 04:38:15,239] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-757#&gl=jp&num=100 via proxy:direct try 2 [2022-02-03 04:38:16,778] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[502] exception=[none] [2022-02-03 04:38:16,778] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-757#&gl=jp&num=100 via proxy:direct try 3 [2022-02-03 04:38:18,313] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[502] exception=[none] [2022-02-03 04:38:18,313] [google-0] WARN c.s.s.t.g.GoogleTaskRunnable - scrap failed for #OBF#search-757# because of ERROR_NETWORK [2022-02-03 04:38:18,316] [google-0] WARN c.s.s.t.g.GoogleTaskRunnable - no more proxy, stopping the thread [2022-02-03 04:38:18,316] [google-0] INFO c.s.s.t.g.GoogleTaskRunnable - google thread stopped [2022-02-03 04:38:18,319] [Thread-28] WARN c.s.s.t.g.GoogleTask - 1 proxies failed during the task [2022-02-03 04:38:18,319] [Thread-28] WARN c.s.s.t.g.GoogleTask - 527 searches have not been checked
1,000個ほどのキーワードのちょうど半分位終わったところで、上の3、5、7行目の502というステータスコードを3回連続受けて、最終的に8行目のERROR_NETWORKが出て処理が終了してしまっていました。
今までSERPOSCPEのログでは見たことがなかったので、理由が全く思いうかばなかったのですが、とりあえず処理を手動で起動してみました。
グローバルメニューの「CHECH RANKS」をクリックして表示される、「Recheck failed/new keywords」を押せばいいのかな、と思いました。ボタンの下に
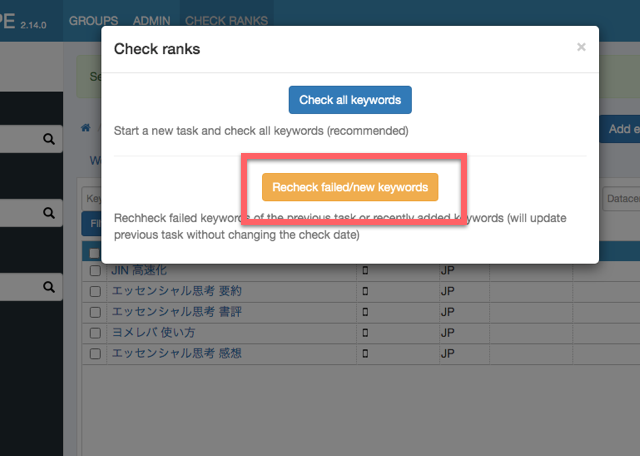
Recheck failed keywords of the previous task or recently added keywords(will update previous task without changing the check date)
前回のタスクで失敗したキーワードか最近追加したキーワードをチェックする(前回のタスクをチェック日付を変えずに更新する)
と書かれています。(和訳は私による)
ただ、もう一つ似たようなボタンがあったのを思い出しました。「Tasks」をクリックすると表示される画面のそれぞれのタスクの右側に、「Rescan SERP」というボタンがあります。これを押した方がいいのかなという気もしました。(下の画面は今回のエラーのタスクではありません)
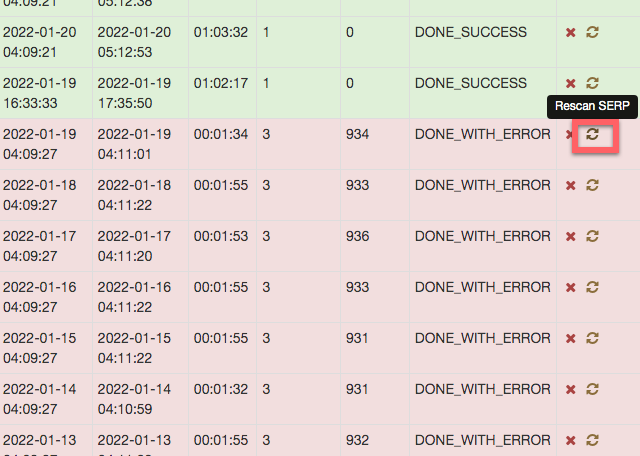
試しに押してみると、下のようなメッセージが表示されました。

SERP rescan is only needed when:
- Website added while a task was running
- Manual import of SERP in the databaseSERP rescanは以下の場合にのみ必要になる
- Websiteがタスクの実行中に追加された
- データベースに手動でSERPをインポートした
と書かれています。(和訳は私による)
よくわからなかったけど、最初に押そうとした「Recheck failed/new keywords」の説明の方がフィットしていたので、「Recheck failed/new keywords」を押しました。
すると、失敗したキーワードだけチェックされました。順調に進んでいます。完了すると、赤くなっていたこの日のタスクが緑に変わりました。もしかしたら、「SERP rescan」を押しても同じ事が起きるのかもしれませんが。
さて、502というステータースコードは何だったのでしょうか?調べたところ、サーバー側(つまりGoogle側)の問題だそうです。
つまり、こちらでは何もできません。もしかしたらGoogleで障害が発生していたのかもしれません。何時間か経って、手動で実行した時には障害が直っていて、適切にチェックできたと推察されます。
とはいえ、GRCは何年も使ってもこのようなことはなかったと思うので、ちょっと不安になりました。もし障害が発生していたら、GRCでも同じようにチェックができなくなるはずなのですが。今回は相当タイミング悪く障害が起きていたのかなと思いたいです。もしくは、GRCの時もこのように処理が止まっていたのかもしれないですが、自動的にある程度の時間を待って実行し直すプログラムなどがあり、うまく502エラーに対処していたのかもしれません。
この502エラーが他に起きていないか気になったので、ログを調べてみました。すると、この日のログの処理が落ちる前に3回ほど発生していました。しかし、そこでは処理は落ちていなかったのです。例えば、以下の3行目です。
[2022-02-03 04:15:08,677] [google-0] INFO c.s.s.t.g.GoogleTaskRunnable - search "#OBF#search-656#" | try 1 | total search done : 84/969 [2022-02-03 04:15:08,677] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-656#&gl=jp&num=100 via proxy:direct try 1 [2022-02-03 04:15:10,380] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[502] exception=[none] [2022-02-03 04:15:10,380] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-656#&gl=jp&num=100 via proxy:direct try 2 [2022-02-03 04:15:11,341] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[200] exception=[none] [2022-02-03 04:15:11,346] [google-0] TRACE c.s.s.s.g.s.GoogleScraper - sleeping 5000 milliseconds
しかし、5行目を見て頂くとわかるように、2回目のtryだと200ステータスが返ってきており、正常にチェックできているのです。
一つのキーワードにつき、うまくチェックできない場合、3回までGoogleへのアクセスをtryします。処理が落ちることになったキーワードでは、3回とも502が返ってきたため落ちました。しかし、その前に実行された落ちなかった3つのキーワードでは、すべて2回目のtryで200が返ってきていました。
ということは、この日、断続的に502が発生するタイミングがあったり、復旧したりというのを繰り返していたのでしょう。運悪く502の状態が長く続いて3回のtryがその時間帯に入ってしまって落ちてしまったということでしょう。
ちなみに、この日以外の過去のログも見て、502が発生していないか確認したところ、発生していませんでした。なので、かなり稀なケースと言えると考えています。
ただ、また発生しない保証はありません。この事象に対して設定で何かできないかと考え、設定画面を見てみました。「ADMIN」というグローバルメニューから「Google」をクリックします。
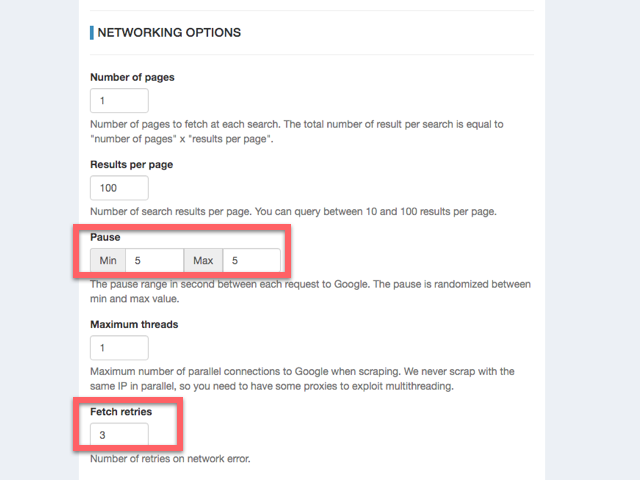
するとtryの回数は3回で固定だと思っていたのですが、上のように「Fetch retries」という値で変えられることがわかりました。なので、これを10に変えてみました。3回のうちには502から復旧しないが、10回やるうちに復旧するかもしれないかなと考えたので。
ちなみに、この数値を増やしても処理時間が大幅に伸びることはないと考えています。というのは、基本的にほとんどのキーワードは1アクセスで成功しています。稀に502などが発生し、その時だけretryが発生するからです。
また、今回の件とは関係無いのですが、この画面で一つ気になったのが、「Pause」の「Min」と「Max」という設定値です。今まで、Googleへのアクセスは「5秒置き」に固定されていたのはMinとMaxが両方とも5になっていたからということがわかりました。この二つの値を別のものにすれば、その間に入る乱数を毎回発生させ、その時間だけ置く、というようにできるようです。
Googleから見れば、毎回カチッと全く同じ秒数を置いてアクセスしてくる人がいたら、ボットだと判断しやすくなるのではないでしょうか。ボットだと判断されると私のサーバーのIPアドレスをブラックリストに入れられて、アクセスできなくされてしまうかもしれません。なので、ここをMinに4、Maxに6を入れました。
ANTI CAPTCHAとのデータ連携でタスクが落ちた?
さらに5日後また「Fiailure」と表示され、確認するとタスクが落ちていました。ログをみると、7行目以降のまだ見たことのないERRORが発生しています。
[2022-02-08 04:10:56,964] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-77#&gl=jp&num=100 via proxy:direct try 1 [2022-02-08 04:10:57,474] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[302] exception=[none] [2022-02-08 04:10:57,841] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT[refetch] status=[302] exception=[none] [2022-02-08 04:10:57,841] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - captcha form detected via proxy:direct [2022-02-08 04:10:57,877] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - trying with captcha recaptcha [2022-02-08 04:10:57,877] [google-0] INFO c.s.s.s.c.s.RandomCaptchaSolver - trying anticaptcha [2022-02-08 04:10:58,808] [google-0] ERROR c.s.s.t.g.GoogleTaskRunnable - unhandled exception, aborting the thread java.lang.ClassCastException: java.lang.Long cannot be cast to java.lang.Integer at com.serphacker.serposcope.scraper.captcha.solver.AntiCaptchaSolver.solve(AntiCaptchaSolver.java:197) ~[serposcope-2.15.0.jar:na] at com.serphacker.serposcope.scraper.captcha.solver.RandomCaptchaSolver.solve(RandomCaptchaSolver.java:47) ~[serposcope-2.15.0.jar:na] at com.serphacker.serposcope.scraper.google.scraper.GoogleScraper.recaptchaForm(GoogleScraper.java:546) ~[serposcope-2.15.0.jar:na] at com.serphacker.serposcope.scraper.google.scraper.GoogleScraper.handleCaptchaRedirect(GoogleScraper.java:487) ~[serposcope-2.15.0.jar:na] at com.serphacker.serposcope.scraper.google.scraper.GoogleScraper.downloadSerp(GoogleScraper.java:185) ~[serposcope-2.15.0.jar:na] at com.serphacker.serposcope.scraper.google.scraper.GoogleScraper.scrap(GoogleScraper.java:101) ~[serposcope-2.15.0.jar:na] at com.serphacker.serposcope.task.google.GoogleTaskRunnable.run(GoogleTaskRunnable.java:99) ~[serposcope-2.15.0.jar:na] at java.lang.Thread.run(Thread.java:748) [na:1.8.0_312] [2022-02-08 04:10:58,813] [google-0] INFO c.s.s.t.g.GoogleTaskRunnable - google thread stopped [2022-02-08 04:10:58,816] [Thread-34] WARN c.s.s.t.g.GoogleTask - 0 proxies failed during the task
今まではタスクが落ちていてもWARNだったのでERRORというのはもっと深刻なのかと少し焦りました。
よく見ると、ANTI CAPTCHAが起動したタイミングで起きています。"java.lang.Long cannot be cast to java.lang.Integer"とあるので、期待したデータ形式じゃないデータを受け取ってしまったことによって発生したと考えられます。
フォーラムを確認してもまだ誰も何の報告もしていません。ANTI CAPTCHA側の問題かもしれないので、そちらの管理画面を開いてみても特に何のお知らせもありません。
とりあえず、手動で実行しなおしてみたところ、やはり同じエラーが発生します。時間がなかったのでとりあえずは放置しました。
数時間後、ANTI CAPTCHA以外のsolverを使えばいいのかな、とか対応を考えました。もしそれでも同じことが発生するなら、GRCに戻らなきゃダメかなと暗い気持ちになっていました。とりあえず、何も変えずにもう一回だけ手動実行してみることにしました。
すると、なんと正常にタスクが全て完了しました。ANTI CAPTCHAも1回起動して、正常に完了していました。ますますわからなくなり、余計に不安になりました。
翌日、なんとなくANTI CAPTCHAの管理画面を開いてみると、1件お知らせが来ていました。通知のアイコンをクリックしてそれを開くと、以下のようなメッセージが表示されました。
Problem with bigInt resolved
Today some of our customers had problems with our API. When a new task was created, API returned taskId which had value larger than 2147483647, which was not supported in those customers apps. Their software was converting this value to a negative integer like -2152295413 and they couldn't request task results with this ID.
We've reset the task id counter and now all IDs are generated in range from 0 to 2147483647. Your apps should start working again without issues. We'll monitor this in the future and will reset the counter, but if you'd like to improve this moment, then ask your developer to implement support of bigint values for our task IDs.
Previously there were no issues with this because we were restarting database server more frequently and ID counter was resetting automatically.
OK
要するに、ANTI CAPTCHA側が返すタスクのIDがある値を超える値(bigInt)の場合、SERPOSCOPE側が負の値に変換してしまうので、エラーが発生してしまうということです。今回はANTI CAPTCHA側が対応し、IDをリセットして小さい値に戻したのでエラーが発生しなくなったということです。問題発生の翌日には対応したのはすごく早いですね。ANTI CAPTCHA側にとってはSERPOSCOPEのユーザは無視できない程大きいのでしょう。SERPOSCOPEがbigIntを扱えないのが原因だ!と言って問題を放置していたら、他のsolver業者にみんな乗り換えちゃいますからね。
とはいえ、本質的な問題はSERPOSCOPEがbigIntを扱えないことな気もするので、改修をするべきかもしれません。
あと、Errorが起きても、処理を全て落とすのではなく、別のsolverを起動するなど、処理を続ける工夫があってもいいかもしれません。(もしかしたらそうなってるのかな?別のsolverを設定していないのでわかりません)
このタイミングでフォーラムをのぞくと、同じエラーを報告する人がいたので、上記のことを教えてあげました。

とりあえず、原因がわかったので安心しました。しかし、このようなことでしばしば問題が起きると面倒だな、という気もします。
とはいえ、SERPOSCOPEは必ず毎日実行されるのに対して、GRCは気が向いた時にパソコンを起動した日にしか実行しません。なので、SERPOSCPEの方が問題を見る機会は多くなってしまうのは仕方ない、とも言えるので、もう少し長い目で見てあげることにします。
ある日404エラー発生。Javaプロセスが落ちた?
ある日ブラウザからアクセスすると404 Not Foundの画面が表示されました。
また不具合かー、と思って気分が落ち込みましたが、冷静さを取り戻して原因究明に取り組みました。
iPhoneからもアクセスしてみると、ベーシック認証をした後は、同じように404 Not Foundの画面が表示されました。
この画面はNginxが出している画面なのでサーバーは落ちておらず、Nginxまでは動いているということです。なので、Javaのプロセスが落ちているのかな、と推測できます。
ターミナルからサーバーにログインして確認していきます。
$ ssh -i private_key.txt centos@**.**.**.** $ sudo su -
SERPOSCOPEのプロセスの存在を確認します。
# ps -ef | grep java root 230478 230458 0 20:36 pts/1 00:00:00 grep --color=auto java
やはりプロセスがなくなっています。
なので、またSERPOSCOPEを起動するコマンドを実行します。ファイル名のバージョン番号はご自身の環境のもに変えて下さい。
# nohup java -jar /var/www/serposcope/serposcope-2.15.0.jar &
これでまた正常に動き出します。
とはいえ、原因特定&再発防止しなければなりません。
プロセスが落ちた時の状況がわかるログが見たいところです。どこにログがあるかを調べていたところ、プロセスが落ちた場合は、以下の記事にあるようにhs_err_pid*.logというようなファイル名でログが生成されるらしいのですが、みつかりません。
よくわからなかったのですが、サーバー全体のログが集まっているように見えた/var/logの中を探すことにしました。タイムスタンプが新しいファイルから探して行きます。
# cd /var/log # ls -ltl total 14928 -rw-------. 1 root root 782654 Mar 2 21:05 secure -rw-------. 1 root utmp 178176 Mar 2 21:05 btmp -rw-r--r--. 1 root root 27979 Mar 2 21:01 cron -rw-------. 1 root root 45701 Mar 2 20:48 messages -rw-rw-r--. 1 root utmp 292292 Mar 2 20:48 lastlog -rw-rw-r--. 1 root utmp 8832 Mar 2 20:48 wtmp -rw-r--r--. 1 root root 554926 Mar 2 20:29 dnf.log -rw-r--r--. 1 root root 76039 Mar 2 20:29 dnf.rpm.log -rw-r--r--. 1 root root 793218 Mar 2 20:29 dnf.librepo.log -rw-------. 1 root root 1380 Mar 2 18:41 hawkey.log (以後省略)
すると、messagesというファイル内に怪しい部分をみつけました。
# cat messages
これでも抜粋ですが、長くてすみません。
Mar 1 05:22:17 i-14100000241979 systemd[1]: Starting dnf makecache... Mar 1 05:22:18 i-14100000241979 dnf[227197]: CentOS Stream 8 - AppStream 6.2 kB/s | 4.4 kB 00:00 Mar 1 05:22:26 i-14100000241979 dnf[227197]: CentOS Stream 8 - AppStream 2.5 MB/s | 20 MB 00:08 Mar 1 05:25:07 i-14100000241979 kernel: pool-2-thread-1 invoked oom-killer: gfp_mask=0x6200ca(GFP_HIGHUSER_MOVABLE), order=0, oom_score_adj=0 Mar 1 05:25:07 i-14100000241979 kernel: CPU: 0 PID: 99819 Comm: pool-2-thread-1 Kdump: loaded Not tainted 4.18.0-277.el8.x86_64 #1 Mar 1 05:25:07 i-14100000241979 kernel: Hardware name: Red Hat KVM, BIOS 0.5.1 01/01/2011 Mar 1 05:25:07 i-14100000241979 kernel: Call Trace: Mar 1 05:25:07 i-14100000241979 kernel: dump_stack+0x5c/0x80 Mar 1 05:25:07 i-14100000241979 kernel: dump_header+0x4a/0x1db Mar 1 05:25:07 i-14100000241979 kernel: oom_kill_process.cold.32+0xb/0x10 Mar 1 05:25:07 i-14100000241979 kernel: out_of_memory+0x1ab/0x4a0 Mar 1 05:25:07 i-14100000241979 kernel: __alloc_pages_slowpath+0xc02/0xd20 Mar 1 05:25:07 i-14100000241979 kernel: __alloc_pages_nodemask+0x283/0x2c0 Mar 1 05:25:07 i-14100000241979 kernel: pagecache_get_page+0xc0/0x2e0 Mar 1 05:25:07 i-14100000241979 kernel: filemap_fault+0x79e/0xa20 Mar 1 05:25:07 i-14100000241979 kernel: ? __mod_memcg_lruvec_state+0x21/0x100 Mar 1 05:25:07 i-14100000241979 kernel: ? page_add_file_rmap+0x12a/0x190 Mar 1 05:25:07 i-14100000241979 kernel: ? alloc_set_pte+0x21c/0x440 Mar 1 05:25:07 i-14100000241979 kernel: ? _cond_resched+0x15/0x30 Mar 1 05:25:07 i-14100000241979 kernel: __xfs_filemap_fault+0x6d/0x200 [xfs] Mar 1 05:25:07 i-14100000241979 kernel: __do_fault+0x36/0xd0 Mar 1 05:25:07 i-14100000241979 kernel: __handle_mm_fault+0x9f9/0xc20 Mar 1 05:25:07 i-14100000241979 kernel: handle_mm_fault+0xc2/0x1d0 Mar 1 05:25:07 i-14100000241979 kernel: __do_page_fault+0x21b/0x4b0 Mar 1 05:25:07 i-14100000241979 kernel: do_page_fault+0x37/0x130 Mar 1 05:25:07 i-14100000241979 kernel: ? page_fault+0x8/0x30 Mar 1 05:25:07 i-14100000241979 kernel: page_fault+0x1e/0x30 Mar 1 05:25:07 i-14100000241979 kernel: RIP: 0033:0x7f847c8fcaf5 Mar 1 05:25:07 i-14100000241979 kernel: Code: Unable to access opcode bytes at RIP 0x7f847c8fcacb. Mar 1 05:25:07 i-14100000241979 kernel: RSP: 002b:00007f843b8ef4e0 EFLAGS: 00010246 Mar 1 05:25:07 i-14100000241979 kernel: RAX: 0000000000000008 RBX: 00007f843b8f04a0 RCX: 0000000000000000 Mar 1 05:25:07 i-14100000241979 kernel: RDX: 00007f843b8f04a0 RSI: 00007f847ca64584 RDI: 00007f84601f3d10 Mar 1 05:25:07 i-14100000241979 kernel: RBP: 00007f843b8ef520 R08: 0000000000000000 R09: 0000000000000002 Mar 1 05:25:07 i-14100000241979 kernel: R10: 0000000000000008 R11: 0000000000000073 R12: 00007f84601f3618 Mar 1 05:25:07 i-14100000241979 kernel: R13: 00007f84601f3648 R14: 0000000000000002 R15: 0000000000000001 Mar 1 05:25:07 i-14100000241979 kernel: Mem-Info: Mar 1 05:25:07 i-14100000241979 kernel: active_anon:3281 inactive_anon:169441 isolated_anon:0#012 active_file:0 inactive_file:3236 isolated_file:6#012 unevictable:0 dirty:0 writeback:0#012 slab_reclaimable:5615 slab_unreclaimable:8149#012 mapped:1404 shmem:10853 pagetables:1951 bounce:0#012 free:10148 free_pcp:0 free_cma:0 Mar 1 05:25:07 i-14100000241979 kernel: Node 0 active_anon:13124kB inactive_anon:677764kB active_file:0kB inactive_file:12944kB unevictable:0kB isolated(anon):0kB isolated(file):24kB mapped:5616kB dirty:0kB writeback:0kB shmem:43412kB shmem_thp: 0kB shmem_pmdmapped: 0kB anon_thp: 421888kB writeback_tmp:0kB all_unreclaimable? no Mar 1 05:25:07 i-14100000241979 kernel: Node 0 DMA free:3656kB min:760kB low:948kB high:1136kB active_anon:0kB inactive_anon:11160kB active_file:0kB inactive_file:196kB unevictable:0kB writepending:0kB present:15992kB managed:15360kB mlocked:0kB kernel_stack:0kB pagetables:136kB bounce:0kB free_pcp:0kB local_pcp:0kB free_cma:0kB Mar 1 05:25:07 i-14100000241979 kernel: lowmem_reserve[]: 0 726 726 726 726 Mar 1 05:25:07 i-14100000241979 kernel: Node 0 DMA32 free:36936kB min:36940kB low:46172kB high:55404kB active_anon:13124kB inactive_anon:666604kB active_file:0kB inactive_file:12740kB unevictable:0kB writepending:0kB present:1032172kB managed:812960kB mlocked:0kB kernel_stack:2096kB pagetables:7668kB bounce:0kB free_pcp:0kB local_pcp:0kB free_cma:0kB Mar 1 05:25:07 i-14100000241979 kernel: lowmem_reserve[]: 0 0 0 0 0 Mar 1 05:25:07 i-14100000241979 kernel: Node 0 DMA: 10*4kB (UM) 4*8kB (U) 4*16kB (UM) 10*32kB (U) 4*64kB (UM) 3*128kB (U) 4*256kB (UM) 1*512kB (M) 1*1024kB (U) 0*2048kB 0*4096kB = 3656kB Mar 1 05:25:07 i-14100000241979 kernel: Node 0 DMA32: 906*4kB (UME) 819*8kB (UME) 496*16kB (UME) 165*32kB (UME) 108*64kB (UME) 42*128kB (UME) 3*256kB (M) 1*512kB (M) 0*1024kB 0*2048kB 0*4096kB = 36960kB Mar 1 05:25:07 i-14100000241979 kernel: Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=2048kB Mar 1 05:25:07 i-14100000241979 kernel: 14093 total pagecache pages Mar 1 05:25:07 i-14100000241979 kernel: 0 pages in swap cache Mar 1 05:25:07 i-14100000241979 kernel: Swap cache stats: add 0, delete 0, find 0/0 Mar 1 05:25:07 i-14100000241979 kernel: Free swap = 0kB Mar 1 05:25:07 i-14100000241979 kernel: Total swap = 0kB Mar 1 05:25:07 i-14100000241979 kernel: 262041 pages RAM Mar 1 05:25:07 i-14100000241979 kernel: 0 pages HighMem/MovableOnly Mar 1 05:25:07 i-14100000241979 kernel: 54961 pages reserved Mar 1 05:25:07 i-14100000241979 kernel: 0 pages hwpoisoned Mar 1 05:25:07 i-14100000241979 kernel: Tasks state (memory values in pages): Mar 1 05:25:07 i-14100000241979 kernel: [ pid ] uid tgid total_vm rss pgtables_bytes swapents oom_score_adj name Mar 1 05:25:07 i-14100000241979 kernel: [ 608] 0 608 30130 1479 249856 0 0 systemd-journal Mar 1 05:25:07 i-14100000241979 kernel: [ 662] 32 662 16791 195 167936 0 0 rpcbind Mar 1 05:25:07 i-14100000241979 kernel: [ 664] 0 664 35437 208 155648 0 -1000 auditd Mar 1 05:25:07 i-14100000241979 kernel: [ 666] 0 666 12136 90 147456 0 0 sedispatch Mar 1 05:25:07 i-14100000241979 kernel: [ 677] 0 677 31539 700 245760 0 -1000 systemd-udevd Mar 1 05:25:07 i-14100000241979 kernel: [ 701] 0 701 101930 514 446464 0 0 sssd Mar 1 05:25:07 i-14100000241979 kernel: [ 707] 81 707 21260 247 163840 0 -900 dbus-daemon Mar 1 05:25:07 i-14100000241979 kernel: [ 713] 998 713 404526 2373 331776 0 0 polkitd Mar 1 05:25:07 i-14100000241979 kernel: [ 721] 992 721 29974 134 151552 0 0 chronyd Mar 1 05:25:07 i-14100000241979 kernel: [ 729] 991 729 40036 205 208896 0 0 rngd Mar 1 05:25:07 i-14100000241979 kernel: [ 752] 0 752 104632 728 446464 0 0 sssd_be Mar 1 05:25:07 i-14100000241979 kernel: [ 762] 0 762 107533 513 479232 0 0 sssd_nss Mar 1 05:25:07 i-14100000241979 kernel: [ 775] 0 775 25924 576 221184 0 0 systemd-logind Mar 1 05:25:07 i-14100000241979 kernel: [ 885] 0 885 150347 621 380928 0 0 NetworkManager Mar 1 05:25:07 i-14100000241979 kernel: [ 889] 0 889 156590 3313 434176 0 0 tuned Mar 1 05:25:07 i-14100000241979 kernel: [ 895] 0 895 77888 165 180224 0 0 gssproxy Mar 1 05:25:07 i-14100000241979 kernel: [ 942] 0 942 62937 1854 266240 0 0 rsyslogd Mar 1 05:25:07 i-14100000241979 kernel: [ 948] 0 948 61679 217 106496 0 0 crond Mar 1 05:25:07 i-14100000241979 kernel: [ 949] 0 949 56497 29 77824 0 0 agetty Mar 1 05:25:07 i-14100000241979 kernel: [ 950] 0 950 56587 28 69632 0 0 agetty Mar 1 05:25:07 i-14100000241979 kernel: [ 1112] 0 1112 23078 233 196608 0 -1000 sshd Mar 1 05:25:07 i-14100000241979 kernel: [ 4592] 1000 4592 25217 375 233472 0 0 systemd Mar 1 05:25:07 i-14100000241979 kernel: [ 4596] 1000 4596 45558 1197 327680 0 0 (sd-pam) Mar 1 05:25:07 i-14100000241979 kernel: [ 15600] 0 15600 29787 530 221184 0 0 nginx Mar 1 05:25:07 i-14100000241979 kernel: [ 15601] 990 15601 37973 691 278528 0 0 nginx Mar 1 05:25:07 i-14100000241979 kernel: [ 99793] 0 99793 610267 115105 1273856 0 0 java Mar 1 05:25:07 i-14100000241979 kernel: [ 227197] 0 227197 225091 30116 983040 0 0 dnf Mar 1 05:25:07 i-14100000241979 kernel: oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/user.slice/user-1000.slice/session-3.scope,task=java,pid=99793,uid=0 Mar 1 05:25:07 i-14100000241979 kernel: Out of memory: Killed process 99793 (java) total-vm:2441068kB, anon-rss:460420kB, file-rss:0kB, shmem-rss:0kB, UID:0 pgtables:1244kB oom_score_adj:0 Mar 1 05:25:07 i-14100000241979 kernel: oom_reaper: reaped process 99793 (java), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB Mar 1 05:25:07 i-14100000241979 systemd[1]: session-3.scope: Succeeded. Mar 1 05:25:07 i-14100000241979 systemd-logind[775]: Removed session 3. Mar 1 05:25:07 i-14100000241979 systemd[1]: Stopping User Manager for UID 1000... Mar 1 05:25:07 i-14100000241979 systemd[4592]: Stopped target Default. Mar 1 05:25:07 i-14100000241979 systemd[4592]: Stopped target Basic System. Mar 1 05:25:07 i-14100000241979 systemd[4592]: Stopped target Timers. Mar 1 05:25:07 i-14100000241979 systemd[4592]: grub-boot-success.timer: Succeeded. Mar 1 05:25:07 i-14100000241979 systemd[4592]: Stopped Mark boot as successful after the user session has run 2 minutes. Mar 1 05:25:07 i-14100000241979 systemd[4592]: Stopped target Paths. Mar 1 05:25:07 i-14100000241979 systemd[4592]: Stopped target Sockets. Mar 1 05:25:07 i-14100000241979 systemd[4592]: dbus.socket: Succeeded. Mar 1 05:25:07 i-14100000241979 systemd[4592]: Closed D-Bus User Message Bus Socket. Mar 1 05:25:07 i-14100000241979 systemd[4592]: Reached target Shutdown. Mar 1 05:25:07 i-14100000241979 systemd[4592]: Starting Exit the Session... Mar 1 05:25:07 i-14100000241979 systemd[4592]: selinux: avc: received policyload notice (seqno=2) Mar 1 05:25:07 i-14100000241979 systemd[4592]: selinux: avc: received policyload notice (seqno=3) Mar 1 05:25:07 i-14100000241979 systemd[4592]: selinux: avc: received policyload notice (seqno=4) Mar 1 05:25:07 i-14100000241979 systemd[1]: user@1000.service: Succeeded. Mar 1 05:25:07 i-14100000241979 systemd[1]: Stopped User Manager for UID 1000. Mar 1 05:25:07 i-14100000241979 systemd[1]: Stopping /run/user/1000 mount wrapper... Mar 1 05:25:07 i-14100000241979 systemd[1]: Removed slice User Slice of UID 1000. Mar 1 05:25:08 i-14100000241979 systemd[1]: run-user-1000.mount: Succeeded. Mar 1 05:25:08 i-14100000241979 systemd[1]: user-runtime-dir@1000.service: Succeeded. Mar 1 05:25:08 i-14100000241979 systemd[1]: Stopped /run/user/1000 mount wrapper. Mar 1 05:25:16 i-14100000241979 dnf[227197]: CentOS Stream 8 - BaseOS 637 B/s | 3.9 kB 00:06 Mar 1 05:27:42 i-14100000241979 dnf[227197]: CentOS Stream 8 - BaseOS 69 kB/s | 9.8 MB 02:26 Mar 1 05:27:42 i-14100000241979 dnf[227197]: Errors during downloading metadata for repository 'baseos': Mar 1 05:27:42 i-14100000241979 dnf[227197]: - Curl error (28): Timeout was reached for http://mirrors.thzhost.com/centos/8-stream/BaseOS/x86_64/os/repodata/5a08020b627f685de23a8eee3c09a3fb703d539400891e9c4afdd4c0f10c9081-primary.xml.gz [Operation too slow. Less than 1000 bytes/sec transferred the last 30 seconds] Mar 1 05:27:42 i-14100000241979 dnf[227197]: - Curl error (28): Timeout was reached for http://mirrors.thzhost.com/centos/8-stream/BaseOS/x86_64/os/repodata/0b5437ef4340cf4c3bf7c6c821ed2e8a89338cdd941ca8a32b5e1830815f036c-comps-BaseOS.x86_64.xml [Operation too slow. Less than 1000 bytes/sec transferred the last 30 seconds] Mar 1 05:27:42 i-14100000241979 dnf[227197]: - Curl error (28): Timeout was reached for http://mirrors.thzhost.com/centos/8-stream/BaseOS/x86_64/os/repodata/33a0459561869aaf956521d0c4d1812f3af2fd7f65940dd4285a041b7bd8c634-filelists.xml.gz [Operation too slow. Less than 1000 bytes/sec transferred the last 30 seconds] Mar 1 05:27:42 i-14100000241979 dnf[227197]: Error: Failed to download metadata for repo 'baseos': Yum repo downloading error: Downloading error(s): repodata/5a08020b627f685de23a8eee3c09a3fb703d539400891e9c4afdd4c0f10c9081-primary.xml.gz - Download failed: Curl error (28): Timeout was reached for http://mirrors.thzhost.com/centos/8-stream/BaseOS/x86_64/os/repodata/5a08020b627f685de23a8eee3c09a3fb703d539400891e9c4afdd4c0f10c9081-primary.xml.gz [Operation too slow. Less than 1000 bytes/sec transferred the last 30 seconds] Mar 1 05:27:42 i-14100000241979 systemd[1]: dnf-makecache.service: Main process exited, code=exited, status=1/FAILURE Mar 1 05:27:42 i-14100000241979 systemd[1]: dnf-makecache.service: Failed with result 'exit-code'. Mar 1 05:27:42 i-14100000241979 systemd[1]: Failed to start dnf makecache.
まず、85行目で「Out of memory」が発生しJavaのプロセスがkillされていることがわかります。この上の方を見ていくと、4行目でoom-killerが起動しています。oom-killerはメモリーが足りなくなった時に、自動的にメモリーを多く消費しているプロセスをkillするものです。
49、50行目を読むと、swapがであることがわかります。以下の記事に沿ってswapを設定することにしました。
【AWS】SpringBootアプリが不定期で落ちるので、原因を探ってみた【Linux】
以下でswapのファイルを作ります。今回は1GB分作ります。
# dd if=/dev/zero of=/var/swap bs=1M count=1024 1024+0 records in 1024+0 records out 1073741824 bytes (1.1 GB, 1.0 GiB) copied, 9.29488 s, 116 MB/s # # # mkswap /var/swap mkswap: /var/swap: insecure permissions 0644, 0600 suggested. Setting up swapspace version 1, size = 1024 MiB (1073737728 bytes) no label, UUID=9a5e31c8-4ece-48ae-8b89-94cb149c800f
パーミッションを変えたほうがいいというメッセージが出たので変えます。
# chmod 600 /var/swap
スワップファイルを有効にします。
# swapon /var/swap
確認します。これはswapを有効にする前にも見ておくべきでした。
# free -ht
total used free shared buff/cache available
Mem: 808Mi 369Mi 68Mi 42Mi 370Mi 280Mi
Swap: 1.0Gi 0.0Ki 1.0Gi
Total: 1.8Gi 370Mi 1.1Gi
これでしばらく同じことが発生しないか様子をみます。
ただ、この対処策はディスクから1GB分をswapとして確保しておくすることになるで、保存できるデータが1GB分少なくなることを意味します。
ちなみに、messagesの問題発生部分をよく読むと、dnfが自動で起動した時に発生していることがわかります。なので、以下の記事のようにdnfの自動起動自体を停止するという解決策も考えられます。
systemdのtimerでdnfのアップデート確認が自動で行われていた
とはいえ、この解決策は、OSやモジュールなどを自動でアップデートしてくれる機能を止めることになるので、定期的に手動でのアップデートが必要になるということです。手動で実行する際も、swapが足りなくなる可能性もあるので、やはりswapを設定する解決策の方が本質的かもしれません。
Anti Captchaのワーカーが足りなくてエラーが発生
久しぶりにSERPOSCOPEを開いてみると、以下のように少し前にエラーが発生していて一括処理が落ちていました。
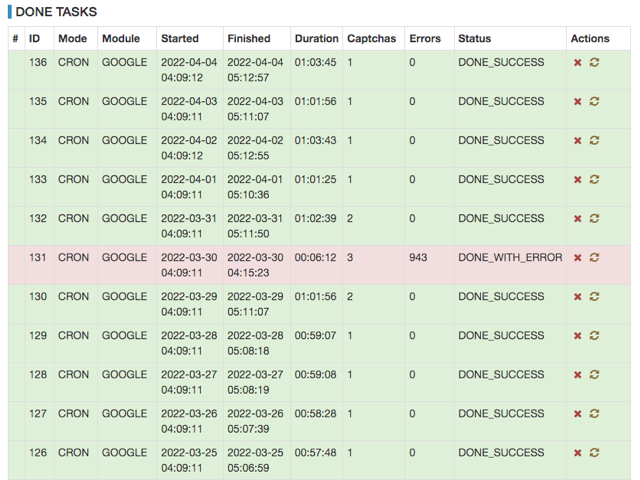
落ちている日が1日だけで、それ以降は正常に完了しているのが不思議でした。
ログを確認してみると以下のようになっていました。
[2022-03-30 04:13:50,408] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=#OBF#search-458#&gl=jp&num=100 via proxy:direct try 3
[2022-03-30 04:13:50,915] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[302] exception=[none]
[2022-03-30 04:13:51,344] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT[refetch] status=[302] exception=[none]
[2022-03-30 04:13:51,344] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - captcha form detected via proxy:direct
[2022-03-30 04:13:51,381] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - trying with captcha recaptcha
[2022-03-30 04:13:51,382] [google-0] INFO c.s.s.s.c.s.RandomCaptchaSolver - trying anticaptcha
[2022-03-30 04:13:57,015] [google-0] DEBUG c.s.s.s.c.s.AntiCaptchaSolver - server is overloaded "{"errorId":2,"errorCode":"ERROR_NO_SLOT_AVAILABLE","errorDescription":"No idle workers are available at the moment. Please try a bit later or increase your maximum bid in menu Settings - API Setup in Anti-Captcha Customers Area."}", sleeping 5000 ms
[2022-03-30 04:14:06,187] [google-0] DEBUG c.s.s.s.c.s.AntiCaptchaSolver - server is overloaded "{"errorId":2,"errorCode":"ERROR_NO_SLOT_AVAILABLE","errorDescription":"No idle workers are available at the moment. Please try a bit later or increase your maximum bid in menu Settings - API Setup in Anti-Captcha Customers Area."}", sleeping 10000 ms
[2022-03-30 04:14:21,430] [google-0] DEBUG c.s.s.s.c.s.AntiCaptchaSolver - server is overloaded "{"errorId":2,"errorCode":"ERROR_NO_SLOT_AVAILABLE","errorDescription":"No idle workers are available at the moment. Please try a bit later or increase your maximum bid in menu Settings - API Setup in Anti-Captcha Customers Area."}", sleeping 15000 ms
[2022-03-30 04:14:36,432] [google-0] DEBUG c.s.s.s.c.s.AntiCaptchaSolver - server is overloaded "null", sleeping 20000 ms
[2022-03-30 04:14:59,297] [google-0] DEBUG c.s.s.s.c.s.AntiCaptchaSolver - server is overloaded "{"errorId":2,"errorCode":"ERROR_NO_SLOT_AVAILABLE","errorDescription":"No idle workers are available at the moment. Please try a bit later or increase your maximum bid in menu Settings - API Setup in Anti-Captcha Customers Area."}", sleeping 25000 ms
[2022-03-30 04:15:24,298] [google-0] INFO c.s.s.s.c.s.RandomCaptchaSolver - anticaptcha failed with NETWORK_ERROR
[2022-03-30 04:15:24,299] [google-0] INFO c.s.s.s.c.s.RandomCaptchaSolver - all captcha solver failed
[2022-03-30 04:15:24,299] [google-0] ERROR c.s.s.s.g.s.GoogleScraper - solver can't resolve captcha error = NETWORK_ERROR
[2022-03-30 04:15:24,300] [google-0] WARN c.s.s.t.g.GoogleTaskRunnable - scrap failed for #OBF#search-458# because of ERROR_CAPTCHA_INCORRECT
[2022-03-30 04:15:24,301] [google-0] WARN c.s.s.t.g.GoogleTaskRunnable - no more proxy, stopping the thread
[2022-03-30 04:15:24,302] [google-0] INFO c.s.s.t.g.GoogleTaskRunnable - google thread stopped
[2022-03-30 04:15:24,309] [Thread-65] WARN c.s.s.t.g.GoogleTask - 1 proxies failed during the task
[2022-03-30 04:15:24,309] [Thread-65] WARN c.s.s.t.g.GoogleTask - 943 searches have not been checked
[2022-03-30 04:15:24,309] [Thread-65] INFO c.s.s.t.AbstractTask - task done for module GOOGLE
[2022-03-30 04:15:24,310] [pool-2-thread-1] INFO s.s.CronService - history pruning : 0 runs deleted
[2022-03-30 07:32:08,305] [pool-1-thread-1] INFO s.s.Scheduler - last version 2.15.0 | current version 2.15.0
[2022-03-30 08:43:03,903] [qtp99347477-18902] WARN o.e.j.h.HttpParser - Illegal character 0x16 in state=START for buffer HeapByteBuffer@5775aeb2[p=1,l=243,c=16384,r=242]={\x16<<<\x03\x01\x00\xEe\x01\x00\x00\xEa\x03\x03I\x06\xB2\xF9\xBc\x99i...\xDf\x85\xDa\xC6@\xA8\xB9\xC2+33\xD4:\xB6H>>>7pnejOQ8oOL0xX4-w...\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00}
[2022-03-30 08:43:03,905] [qtp99347477-18902] WARN o.e.j.h.HttpParser - badMessage: 400 Illegal character 0x16 for HttpChannelOverHttp@24023f4e{r=0,c=false,a=IDLE,uri=-}
[2022-03-30 08:43:18,104] [qtp99347477-18903] WARN o.e.j.h.HttpParser - Illegal character 0x16 in state=START for buffer HeapByteBuffer@11b25fbd[p=1,l=243,c=16384,r=242]={\x16<<<\x03\x01\x00\xEe\x01\x00\x00\xEa\x03\x03I\x06\xB2\xF9\xBc\x99i...\xDf\x85\xDa\xC6@\xA8\xB9\xC2+33\xD4:\xB6H>>>AGvVLzAF5mGYP8p2C...\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00}
[2022-03-30 08:43:18,105] [qtp99347477-18903] WARN o.e.j.h.HttpParser - badMessage: 400 Illegal character 0x16 for HttpChannelOverHttp@158dd953{r=0,c=false,a=IDLE,uri=-}
これは繰り返されたエラーの最後の部分です。1行目から14行目までの部分が繰り返され、それ以降は最後の一回にのみ登場し、処理全てが止まってしまっていました。
7行目から複数回表示されるエラーコードにはERROR_NO_SLOT_AVAILABLEとあります。エラーの詳細メッセージでは、
No idle workers are available at the moment. Please try a bit later or increase your maximum bid in menu Settings - API Setup in Anti-Captcha Customers Area.
とあります。
これらのメッセージをもとにGoogleで検索すると、以下のFAQページを見つけました。
このページの「Why do I need a "maximum bid"? Why am I receiving a "no idle workers available" error? Where do I set my bid?」という質問に知りたい事が書いてありました。
簡単に言うと、Anti Captchのワーカーが足りていないということです。ワーカーは世界中にいる実際の人間なので、足りていない時間帯もありますし、タスクの量が多くなり過ぎる時間帯もあるでしょう。足りている時間はデフォルトの料金で処理してくれるのですが、足りていない時は、「maximum bid」という設定値を高くしている人のタスクのみ処理するそうです。私はこの値を設定した記憶がないので、おそらくデフォルト値ですが、5ドルになっていました。
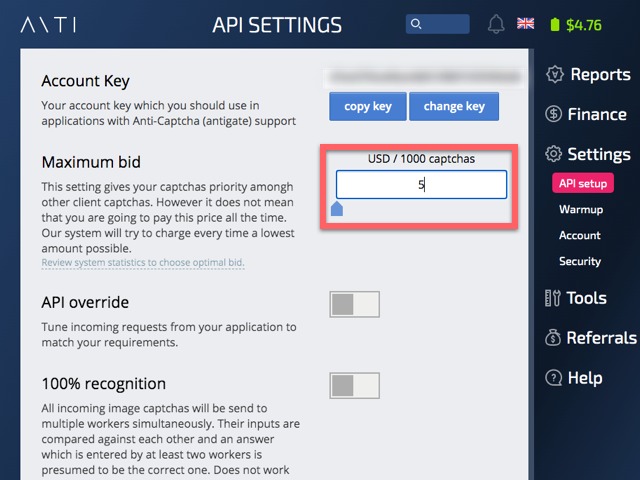
たまたまエラーが起きた日はタスクの量に対してWorkerが足りていなかったのでしょう。それ以降の日は足りていたのでエラーは起きていなかったということです。
対策としては、他のユーザーよりも高いと思われる値をmaximum bidに設定するという手段があります。あと、Anti Captch以外のcaptchaサービスも併せて設定することも考えられます。Anti Captchがダメな場合は、自動的に他のcaptchaサービスを使ってくれます。
とはいえ、今回の理由で処理が落ちた日はかなりレアなので、私の場合は特に何も対処しません。別に何十日に一日くらいチェックできなくても何の問題もないからです。
スポンサーリンク
またGoogleの仕様変更でエラー発生
私のSERPOSCOPEは2022年の6月くらいから動かなくなりました。以下の8行目にあるERROR_CAPTCHA_INCORRECTというエラーが発生したためでです。
[2022-06-03 12:39:02,842] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - GET https://www.google.com/search?q=xxxxxx&gl=fr&num=100 via proxy:direct try 3 [2022-06-03 12:39:03,324] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT status=[302] exception=[none] [2022-06-03 12:39:03,704] [google-0] INFO c.s.s.s.g.s.GoogleScraper - GOT[refetch] status=[302] exception=[none] [2022-06-03 12:39:03,704] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - captcha form detected via proxy:direct [2022-06-03 12:39:03,734] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - trying with captcha recaptcha [2022-06-03 12:39:03,734] [google-0] INFO c.s.s.s.c.s.RandomCaptchaSolver - trying anticaptcha [2022-06-03 12:40:08,338] [google-0] DEBUG c.s.s.s.g.s.GoogleScraper - got captcha response xxxxxxxxxxxx in 64 seconds from anticaptcha [2022-06-03 12:40:09,103] [google-0] WARN c.s.s.t.g.GoogleTaskRunnable - scrap failed for xxxxxx because of ERROR_CAPTCHA_INCORRECT
これは公式のGithubリポジトリのissueでも取り上げられています。
これを読んでいて分かったのが、やはりGoogleの仕様変更があったということです。このページからリンクされている以下の記事によると
Update on Google Search reCAPTCHA V2
Googleへのクエリで num=xx というのをつけられなくなったということです。つけると、reCAPTCHA V2の認証に飛ばされてしまうということです。先ほどのエラーログの1行目を見て頂くと、 num=100 というのがついています。これは100件の検索結果を持って来い!って意味なんですが、よく考えたら、100件の検索結果を求めるのはボットとかプログラムであって、人間ではないですよね。なので規制して当然と言えば当然です。
これに対処するためにいくつか対処法が先ほどのissueで提示されていました。numを10にすれば num=xxつかなくなるとのことなのでそうしました。しかし、10にするとこれまでと同じ100件の検索結果を得るために10倍の回数クエリを発行するということになります。そうすると、チェック時間もかかるだろうし、Anti Captchaの費用も多くなってしまいます。よく考えると100件の検索結果なんて必要なくて、30件くらいでもいいかなと思いました。単純にAnti Capthcaの費用が3倍になるだけなら全く負担にはなりません。なので、設定は以下のようにしました。
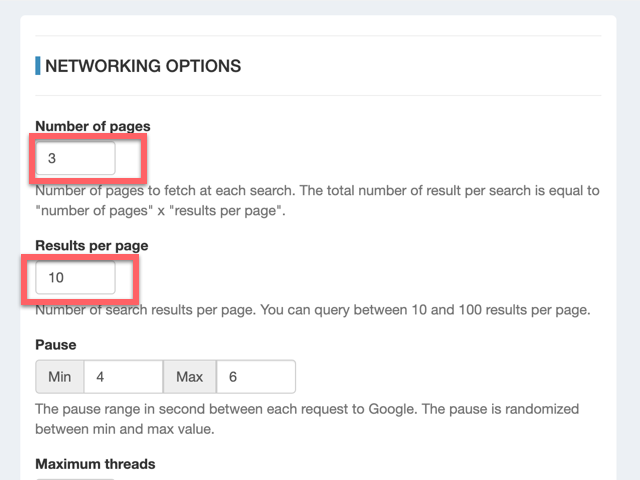
案の定、ERROR_CAPTCHA_INCORRECTで落ちることはなくなりました。しかし、やはりAnti Captchaは3倍では済まない程に消費しており、最初に入金して数ヶ月使っても全然減らなかった約5ドルを数日で使い切ってしまい、reCAPTCHA V2が通らないエラーが発生してしまいました。リクエスト回数が3倍になっただけなのでAnti Captchaの3倍で済むかと思ったのですが、なぜか数十倍のスピードで消費しました。やはりGoogleの仕様変更でreCAPTCHA V2に飛ばされる頻度自体が激増しているのかもしれません。
ここでまた先程のissueを眺めていたら衝撃的なコメントを発見してしまいました
noguespi commented on Jun 11, 2022
For your information, as specified since january 2020 serposcope is no more maintenained and I encourage you to move to another solution.
SERPOSCOPEの管理者曰く、SERPOSCOPEはもうメンテナンスしないので、他のツールに移行してくれ、とのことです。しかも2020年から宣言されていたそうです。
まじか、全然気が付かなかった。 SERPOSCOPEを私が使い始めたのは2020年以降です。公式サイトの目立つところに書いてはいないので、なかなか気付けません。少し不親切ですね。
なので、素直に他のツールを探すことにしました。色々と検討した結果、WineというツールでGRCをMacでも動かせることがわかったので、その方法を採用することにしました。次の記事に詳しく説明します。
[card name=wine-grc]
ちなみに、しばらくすると公式リポジトリのissueで次期バージョンの3についての計画を知りました。もしかしたら、いつかこの問題は解消するかもしれません。
まとめ
SERPOSCOPEの良い点、悪い点についてまとめておきます。
- ソフトウェアは無料なのでサーバ代だけで運用できる
- サーバで運用できるのでPCをいちいち開かなくていい
- WEBアクセスできるのでチームでリモートで管理できる
- 同じキーワードで複数サイトチェックする場合は一度の処理で済む
- Googleのブラックリストに入れられてもVPSを作り直せばすぐに使える
- Googleの仕様変更にも開発側が数日で対応してくれる
- スマホから手軽に確認できる
- YahooやBingには対応していない
- 設定はターミナル作業(黒い画面)が必要になってしまう
- キーワード一括登録時に他の項目もカンマ区切りで入力する必要がある
- 時々エラーが発生する
- エラーで落ちてもメールで通知してくれない
- 人のURLも保存するのでデータ量が多くなりそう
- 自動チェクの頻度は変えられず、毎日が必須。
さいごに
こんな感じで紆余曲折ありましたが、なんとかSERPOSCOPEを使えるようになりました。 GRCとようやくおさらばできます。
さて、検索順位をチェックするのも大事ですが、上位表示するためにのライティングのコツがあります。私が考えたテクニックは自分の「感情」をうまく使うというものです。以下で説明していますので、参考にしてみてください。
[card name=emotion-blog]
The post GRCよりいい?SERPOSCOPEの評判と使い方!使えないなんて嘘! first appeared on WebFood.
]]>The post これからは"感情ブログ"が稼げる理由と書き方 first appeared on WebFood.
]]>私は2015年頃にブログを始めましたが、ブログで稼ぐための文章表現では「感情」が重要だという考えに至りました。その理由を説明します。また、私が考案した方法で書いたブログを"感情ブログ"と読んでいますがその書き方をご説明します
Goolgleのアルゴリズムの変化でまとめ記事が全滅
ブログアフィリエイトは検索エンジンからの集客をメインにしているため、Googleのアルゴリズムに大きく依存します。
2010年代前半はまとめサイトが台頭し、多くのブロガーやアフィリエイターはネット上から収集した情報を一つの記事にまとめるという手法で作った記事を量産していました。このような記事を二次情報といいます。
一つの記事に多くの情報がまとまった記事はわかりやすいというメリットがある反面、ソース(出どころ)がわからない情報が多く、信頼性に不安が持たれました。
2016年頃、Welqなどのまとめサイトが医療系の記事で根拠のない情報を掲載し、大炎上しました。それを機にGoogleのアルゴリズムも改変されまとめ記事は上位表示されないようになっていきました。
ユーザーのリテラリーの向上
Googleのアルゴリズムはユーザーの使い方とともに発展しており、ユーザーの使い方が変化すると、それに最適化するためにGoogle側もアルゴリズムを改変します。なので鶏が先か卵が先かはわかりませんが、ユーザーの使い方とアルゴリズムは互いに影響しあって変化していっています。
ユーザーもまとめ記事などの安易なわかりやすい記事を鵜呑みにするのではなく、ソースを意識して検索するようになったり、まとめられていない一次情報である一般人の感想や体験談をあえて検索するようになりました。つまり、自分で咀嚼して考えるように徐々になってきているということです。昔よりもユーザーの検索リテラシーが向上したと言えます。
なので、Google側も、専門家が書いたとわかる記事、大手企業のドメインの記事、一次情報が記載された記事が上位表示されるようにアルゴリズムを改変していきました。
役割は人柱。体験するとどうなるかを想像したいだけ
先ほど
- 専門家が書いたとわかる記事
- 大手企業のドメインの記事
- 一次情報が記載された記事
とさらっと書きました。
あなたが何らかの領域の専門家であったり、大手企業のWEB担当者であれば、話は簡単です。でも、ほとんどの方がそうではないでしょう。
残された道は「一次情報が記載された記事」しかありません。一次情報とはなんでしょうか?「世の中に最初に出た情報」ということです。実は、専門家や大手企業が出す情報も一次情報と言えます。専門家が世界で一番最初に出した研究結果や考察などはわかりやすいです。大手企業の場合は、例えば「トヨタが〇〇という車を発売」というだけで、もはや一次情報でしょう。そのような一次情報を、その他のメディアが二次情報として加工して発信しています。
そして、「あなたというこの世に1人しかいない人が実際に体験したこと」も一次情報になります。誰かから聞いた話でもなく、想像でもなく、あなたが実際に体験したことを書けば、それが一次情報です。
さて、検索する人はなぜ一次情報を求めているのでしょうか?一言でいうと
人柱
です。
何かを体験する前に、試しに他の誰かに体験してもらって感想を聞きたいのです。それによって、リアルにその体験を想像して、実際に自分でも体験するかを検討したいのです。
その商品を買ったらどうなるのか?
その美容皮膚科で治療を受けたらどうなるのか?
そのプログラミングスクールに通ったらどうなるのか?
そのお店に行ったらどうなるのか?
といったようなことを、まずは自分で体験せずに、他の人に体験して欲しいのです。そしてその詳細な感想を知りたいのです。
感想というのは、主観的なものです。理系の方やアカデミックなライティングに慣れた方は、客観的な数値にのみ価値があると勘違いしやすいですが、ブログで稼ぐためには主観が圧倒的に重要です。
読者は数値だけで言われても、「結局はあなたはどう感じたの?」というのを答えて欲しいからです。
主観というのは、つまりは、感情です。
嬉しい
悲しい
驚く
辛い
ドキドキする
気まずい
といった人間として普通の感情を文章で伝えることが重要になります。
スポンサーリンク
感情で読者の共感を生むと滞在時間が向上
感情はSEO的な効果だけではなく、実際の読者の行動にも影響を与えます。
優れた映画、小説、ゲームは、長時間でもあっという間に過ぎていくのは感情的な体験があるためです。以下はアメリカの映画界で活躍していて"最優秀脚本講師"に選ばれたカール・イグレシアス氏の「『感情』から書く脚本術」からの引用です。
本当に大事なこと、それは脚本を読む人に感情的な体験を提供するということなのだ。読んだ人の心がいろいろと感じたから、それを良く書けた脚本と呼ぶのだ。同じ理由で3時間の長大作があっという間に終わってしまったように感じることもあれば、反対に90分の映画が90時間に感じられることもある。心理学者が映画のことを「感情マシン」と呼ぶのは、まさにそのためなのだ。感情的体験がすべて。その体験を求めて、私たちは映画を観に行く。テレビを観るのも、ゲームをやるのも、小説を読むのも、観劇するのも、スポーツ観戦に行くのも同じ理由だ。それなのに、この感情的反応というものは、なぜか見落とされてしまう。
カール・イグレシアス. 「感情」から書く脚本術 (Japanese Edition) (Kindle の位置No.162-168). Kindle 版.

これは脚本だけでなくブログ記事についても同じことが言えます。
感情表現に共感する読者は、「もっと読みたい、もっと読みたい」としっかり記事を読んでくれて、「この筆者の記事なら他の記事も読んでみたい」と他の記事を読んでもらいやすくなります。結果的にサイトの滞在時間が伸びます。滞在時間が伸びると検索エンジンからの評価が上がり、上位表示されやすくなる、という好循環が生まれます。
こちらが促したい行動をとる確率も向上
筆者に共感した読者は、こちらが促したい行動をとりやすくなります。何かを販売したり申し込んでもらえる確率が上がります。
この理由は心理学の名著「影響力の武器」で説明されている「社会的証明」という心理効果で説明できます。
私達の行動は他者の行動に影響されるという効果です。例えば、駅のホームに向かう途中、周囲の人が小走りになったら、自分も走りたくなる気持ちが働きます。
この効果は参照する他者と自分の類似性が大きいほど効果が大きくなります。つまり自分に似ている人からの影響が大きくなります。年齢、性別、人種、衣服などの類似性がわかりやすいですが、感情の類似性もそれと同等以上に効果があります。
筆者の感情に共感した読者は、「筆者はこの状況ならこのような感情を抱くのか。私と同じだ。」と感じます。なので筆者と同じ行動をとる心理的圧力が働きます。影響力の武器は以下で要約しました。
[card name=influence-science-and-practice]
AIに感情を再現することは当分できない
AIの発達でブログ記事もAIが自動生成する時代がきて、ブロガーの出る幕がなくなってしまうのでは?と心配される方もいるかもしれません。
しかしAIに感情は発生しません。というのはAIには肉体がないためです。
人間の体験というのは肉体があって初めて成立します。
美容皮膚科の治療を受ける、〇〇を食べる、岩盤浴に入る、
というのは、肉体、皮膚、胃袋といったものを持たないAIには体験することができません。
もちろん、大量のデータを用いて、感情をシミュレーションすることはできるのでしょうが、それはデータという一次情報を加工した優秀な二次情報に過ぎません。
AIが感情を生成することができない以上、当分は我々人間が言葉で感情を伝えるしかありません。
そのうち、脳に電極を挿して、ある体験をした時の感覚を数値で計測できる時代になれば、言葉を使って感情を伝える必要はなくなるかもしれませんが、まだ先の話です。
二次情報的なまとめ記事はAIでどんどん生成できるようになるでしょうが、感情を盛り込んだ記事はまだまだ難しいという事です。なので、ブロガーは感情を使って記事を書くことが重要で価値があるということです。
大手企業は感情表現ができないので個人の独壇場
先ほど大手企業のドメインがSEOで強いというお話をしました。しかし、感情表現に関して言えば、大手企業のサイトではなかなかできないのが実情です。
というのは、あなたが働く会社を思い浮かべて欲しいのですが、通常の企業では、感情を殺して働くように要求されています。サイトの運営だけ感情豊かにする、というのは難しいです。もちろん、外部のライターに報酬を払って記事を書いてもらうことはできます。しかし、外部のライターは、お金をもらっているため、その企業に対してネガティブな感情を少しも出すことができないので、自由度が非常に低い感情表現になってしまうでしょう。
なので、個人や零細企業は感情をフルに表現でき独壇場となり、大手企業のサイトを出し抜くことも可能です。
スポンサーリンク
あなたが感じた感情は他の人も感じる可能性が大
私のたった1人の感情なんて価値あるのかな?
そういう風に謙虚になりすぎる方が多いのですが、その必要は全くありません。
例えば、ある商品に対する感情は、良い、悪いなど様々な感想を持つ人がいます。
でも、その商品を使った人が数十万人いたとしたら、数万人くらいはあなたとほとんど同じ感情を抱くはずです。
あなたの感情はその数万人を代表するサンプルとなるので非常に価値があります。読者はいろんなタイプの感情をネット上で読み、そして自分で咀嚼して行動を起こすか判断するので、あなたが他のタイプの感情まで代表する責任は全くないのです。
なので、あなたの感情を素直に表現することに価値があるのです。
先ほど紹介した「『感情』から書く脚本術」でも以下のように書かれています。
読めば興奮するような話を創造する最適な方法は、自分を興奮させることについて書くことだ。自分の本能に逆らってはいけない。自分がよく知っていることを書けというのが一般的な助言だが、私に言わせれば「自分の感情を刺激するもの、惹きつけるものを書け」だ。あなたが一番よく知っているのは、結局あなた自身の感情に他ならないからだ。何しろ、喋る言語は違っても私たちは誰しも、感情という共通言語で物事を感じているのだから。良く書けた脚本イコール感情なわけだが、感情はジャンルを、年齢を、貧富の差を、政治的な境界を超えていく。
カール・イグレシアス. 「感情」から書く脚本術 (Japanese Edition) (Kindle の位置No.682-688). Kindle 版.
感情を伝えるためにストーリーが不可欠
ここまではブログにおける感情の重要性を説明しました。ここからはどのように感情を表現するのかを説明します。
感情を文章で伝えるのに重要なのがストーリーです。日本語でいうと物語ですがストーリーの方がしっくりくるのでストーリーと呼びます。
ストーリーの定義は出来事を時系列順に伝えることだと考えています。
つまり、古い出来事から順に新しい出来事を伝えます。
なぜ、感情を伝えるのにストーリーが重要かと言えば、
ある「感情」を引き起こした「状況」と「出来事」
を読者にリアルに想像させることができるからです。
誰かの感情が動くのは、ある状況で何かが起こるためです。
遠隔から念力で他人が感情を操作することなどできません。感情というのは、ある人物がいてそれをとりまく状況があり何かが起こるために発生します。
映画や演劇や小説で登場人物に共感して心動かされてしまうのは、やはり時系列順に話が進んでいるためでしょう。結末から始まる小説なんてありません。
もちろん、例外的な演出として好奇心を掻き立てるために冒頭に結末を持ってくるストーリーもあります。また、ゴットファーザー2のように、父の若い時代と息子の時代を交互に進めるというような演出もあります。しかし、主要部分は時系列順に出来事が進みます。
「『感情』から書く脚本術」では以下のように書かれています。
「王が死んだ。女王が死んだ」。これでは、ただの年代記だ。しかし「王が死んだ。悲しみにくれた女王が死んだ」とすれば、より満足できる文章になる。原因が付け加えられたからだ。2つの事件が原因によって繋がり、より読者の関心を引き、満足を与えるものになった。だから、ランダムなエピソードの羅列よりも、それぞれの出来事が次の出来事の原因になっているということが明確に理解できるプロットがあった方が、関心を維持しやすい
カール・イグレシアス. 「感情」から書く脚本術 (Japanese Edition) (Kindle の位置No.2225-2229). Kindle 版.
ここでは、出来事と出来事が因果関係によって結ばれていれば、より魅力的な文章になると述べられています。時系列順に出来事が並んでいれば、それぞれが因果関係で結ばれていることがわかりやすくなります。
例えば、ブログの商品やサービスの体験記事の大まかな流れは以下のようになることが多いです。
- 自己紹介
- 状況説明
- 動機
- 調査
- 比較
- 購入、申し込み
- 開封
- 利用
- 利用後どうなったか
- 考察
1→10で時系列順に並んでいることがわかります。それぞれのセクション内でも出来事が時系列で進みます。
会話体や心の声を多用する
時系列順に出来事を並べるという原則とともに重要なのが、会話体や心の声。
これが発生した「感情」に相当します。もちろん
「悲しくなった」
「嬉しくなった」
など直接的に感情を表現してもいいのですが、
『なんでこんなことになってしまったんだよ。俺今まで何してたんだ。』
『やば!今月の俺の営業成績、うちの部署で一位じゃん!今日は飲んで祝うぞー!』
など、その状況での発言や心の声などを書いた方がリアルに感情が想像できます。
鉤括弧で囲ってもいいですし、次のように吹き出しでもいいですし、地の文で書いてしまうのもアリです。
吹き出しは会話体、心の声、どちらでも使えますね。
上級テクニックとしては、感情を行動で表現します。「『感情』から書く脚本術」では以下のように書かれています。
ここでは「語るな、見せろ」の原則に従って、キャラクターの心の中を行動として見せて、今度は読者の感情のツボを突こう。××と感じているなどと書くより、よほど強烈に感情を刺激することができる。キャラクターが怒っているとき、巧い脚本家なら怒りを感じさせる動作で表現する。「彼女は怒っている」などとは死んでも書かない。書くなら「鍋を投げつけて窓を叩き割る」だ。行動は常に台詞より真実を伝えるということを覚えておこう。
カール・イグレシアス. 「感情」から書く脚本術 (Japanese Edition) (Kindle の位置No.4490-4494). Kindle 版.
視覚的描写、感覚的描写を多用する
視覚的描写や感覚的描写も重要です。これは「状況」や「出来事」に相当します。
視覚的描写というのは映像をイメージできるように具体的に表現するということです。
「10時に配達員が商品を届けてくれました」
「10時にインターホンがなり、とびらを開くと50cm四方の重そうなダンボールを抱えた白髪混じりの配達員が笑顔で立っています」
などとした方が、状況を正確に想像させてくれます。
感覚的描写とは視覚以外の描写です。たとえば
「美容皮膚科でのレーザー施術では、パチンという音ともに、ほっぺたが輪ゴムで弾かれたような痛みが数分間にわたり繰り返されます」
という感じです。
スポンサーリンク
語尾が現在系か過去形かは好みによる
ストーリーとして出来事を並べるので、なるべく書いている現在から過去を振り返る表現を使わないようにします。
「たしかあれは17時頃だったと思うのですが」
書いている時点と実際に出来事が起きている時点が違う、というのを読者に意識させる表現は使わないようにします。それを意識させてしまうと途端に今ここで出来事が起きているという臨場感が落ちて、現実に引き戻されてしまうためです。
つまり出来事や感情は、読者の頭の中では「読んでいる時点」で発生しているというのを大事にして文章を書きます。
書いている時点より出来事は当然過去なので通常は語尾を過去形にしがちですが、読者が読んでいる時点に合わせるなら現在系でもよいことになります。例えば、
「10時にインターホンがなり、とびらを開くと50cm四方の重そうなダンボールを抱えた白髪混じりの配達員が笑顔で立っています」
というような感じです。
とはいえ、一般的な小説でも作家の文体の好みによってどちらもあるので、これはあなたの好みでいいと思います。先ほどの例を過去形にすると
「10時にインターホンがなり、とびらを開くと50cm四方の重そうなダンボールを抱えた白髪混じりの配達員が笑顔で立っていました」
となります。
感情を殺して働く現代人にとっては救いになる
ここまではどのように感情を表現するのかを説明しました。
ただ、一般の会社などの職場ではなかなか感情を出す機会は少ないので、いきなり感情を出せと言われて戸惑うかもしれません。
私は専門家ではないので断言はできませんが、日本で自殺率が高いのは、自分の感情に鈍感になることでメンタル的な不調を引き起こしてしまう方が多いからでは、と考えています。
ブログで感情を表現することが習慣になっていくと、普段から自分の感情に対して敏感に気づくようになります。するとメンタルに問題が出る前に自分でケアできるようになってきます。
なので、この方法は、感情に鈍感になってしまった現代人にとってとても良い心のエクササイズになるはずです。
もう少しアフィリエイトに特化した記事の書き方の説明としては以下があります。
[card name=how-to-write-review]
The post これからは"感情ブログ"が稼げる理由と書き方 first appeared on WebFood.
]]>The post JINのプロフ画像のimgタグにloadingをつけるプラグインを作った first appeared on WebFood.
]]>WordPressテーマ「JIN」のサイドバーに表示させるプロフ画像のimgタグにloading="lazy"を付与するプラグインを作りました。
遅延読み込みしなくてPageSpeed Insightsでマイナス要素になる
本サイトもGoogleの公式ツールであるPageSpeed Insightsでの数値改善に取り組んできました。JINもwidht、height、loading要素を付与するなどのアップデートがあり、開発陣もこのあたり意識をしているようです。
でも、なぜかサイドバーに設置するプロフ画像には、width、height要素の付与のみで、loading要素がつきませんでした。
これだとPageSpeed Insightsで「オフスクリーン画像の遅延読み込み 」という項目でひっかかってしまいます。
なので、プラグインを導入するだけで、loading="lazy"を付与するプラグインを作りました。
よければ、本サイトのプロフィール画像のHTMLをChromeのデベロッパーツールなどで確認してみてください。
このプラグインを導入することで「オフスクリーン画像の遅延読み込み 」の項目もクリアできました。
ついでにprofileページがなければリンクしないようにした
ついでにこのプラグインにちょっとした機能を入れました。JIN側のバグを修正したとも言えるかもしれません。
前々から気になっていたのですが、JINは「profile」という投稿をしていると、プロフィール画像にその記事のURLに対してリンクされる仕様になっています。
でももし「profile」という投稿がない場合は、なぜか無関係の記事のURLがリンクされてしまいます。特にprofileという投稿をしない人は多いと思います。これはバグだと思います。
そういう人はおそらく、CSSやJavaScriptでプロフィール画像をクリックできないようにして、しのいでいるのではないでしょうか。私もこれまでそうでした。
読者から見ればそれで全然問題ないのですが、サイドバーからリンクされるということは、サイトの全ページからになるのですごい数のリンクになってしまいます。無駄な発リンクはおそらくGoogleのクローラーさんの混乱の元なので、SEO的にもよろしくないと考えました。
なので、もしprofileという投稿がなければ、どのページにもリンクしない(aタグを出力しない)仕様にしました。もしprofileという投稿があれば、これまで通りその記事にリンクします。
このプラグインを導入すれば適用されます。
zipファイルをアップロードしてインストール
通常のWordPressプラグインは、WordPressの管理画面でプラグインの新規追加画面で検索してボタン一つか二つ押すだけでインストールできます。しかし、このプラグインはまだ公式のWordPressプラグインとして申請していません。
なので、zipファイルになっているプラグインを入手していただき、それをWordPressの管理画面からアップロードしてインストールする、という方法になります。
zipファイルは以下のボタンから無料でダウンロードできます。
ダウンロードしたzipファイルをWordPressの管理画面からアップロードしてインストールします。プラグイン名は「Jin add loading prof img」です。詳しいやり方は次の記事をご覧ください。
JINバージョン: 2.650で動作確認。
スポンサーリンク
もしニーズが大きければ
そこまで機能変更があるプラグインでもないので、アップデートする機会はあまりないと思いますが、zipファイルでの手動インストールだと、アップデート時は面倒です。一度プラグインを削除してから、先ほどと同じ手順でインストールする必要があります。
公式のWordPressプラグインとして申請して認められれば、イントールも更新もボタン1つでできるようになります。
もしニーズが大きいようであれば、申請しようと思います。なので、利用してみて使い勝手が良ければ、ブログやSNSでこのプラグインについて紹介してください!
Twitterの場合は、以下の私のアカウントにメンション頂ければ気付きやすいので助かります。またこのプラグインをアップデートした際は、Twitterでお知らせするのでフォロー頂けたら嬉しいです。
https://twitter.com/tai_tantan
JIN専用のプラグイン他にも作ってます
JINで使える便利なプラグイン他にも作っていますのでご覧ください。
[card name=jin-more-related-entries]
[card name=jin-blog-card-by-name]
[card name=jin-defer-asset]
[card name=loading-img]
カッテネもおすすめ
ちなみに、3000サイト以上にご利用いただいているカッテネというWordPressプラグインも以前作りました。以下のような商品リンクを作るプラグインです。

こちらはJINはもちろん、それ以外のテーマにも対応しています。また、人気が出たので公式のプラグインとして申請したので、ボタン1つでインストールできます。無料なので使ってみてください。
[card name=make-kattene]
増え続けるプラグイン問題への回答
プラグイン無しにはWordPressの運用はできないと思います。私のように、細かい追加機能を自分でプラグインとしてプラグラミングしてしまう人は当然ですが、そうでない人でも、管理画面のプラグイン一覧に数十個並ぶのも普通なのではないでしょうか。
そうすると、非常に見づらくなり、管理しづらくなります。そこで超役立つプラグインがPlugin Groupsというプラグイン。Pluginをグループに分けられ、グループごとに表示できます。例えば、私が作ったプラグインを複数使っている方なら、「WebFood」などとグループを作ってそれに入れてもいいかもしれません。ちなみに、タグのように複数のグループに所属させることが可能なので、柔軟に分類することができます。ちなみに、これは私の作ったプラグインではなく、公式の方法で簡単にインストールできます。
The post JINのプロフ画像のimgタグにloadingをつけるプラグインを作った first appeared on WebFood.
]]>The post JINのヘッダー画像にwidth,height,loadingを付与する方法 first appeared on WebFood.
]]>WordPressテーマ「JIN」のヘッダー画像のimg要素にwidth、height、loading属性を付与する方法をご紹介します。
ヘッダー画像読込時にレイアウトがガクッと動く
昨今はJINもユーザーの体感表示速度の改善に力を入れているようで、アイキャッチ画像やサムネイルにはwidth、height、loadingが付与される変更が行われました。
しかし、なぜかヘッダー画像にはついていません。難易度としてはそんなに変わらないはずなのに、なぜつけなかったのか謎です。
そうすると、ページ表示時にヘッダー画像の領域を事前に確保できないので、途中でレイアウトがガクッと動いてしまい、読者にとっては大きなストレスになります。
私のサイトではこれらの大切な属性を付与することに成功しました。よければChromeのデベロッパーツールなどで私のサイトのトップページにあるヘッダー画像のimgタグを調べてみてください。
すぐ思いつく方法としては、親テーマか子テーマの対応するファイルのimg要素に表示したい画像のheight、widht、loadingを書き込んじゃうことです。でも、もし画像のサイズを変えたらいちいちテーマのファイルも変更しなければいけません。
私の方法では、しっかり画像のサイズを取得して記載するプログラムになっています。今回はこの方法をご紹介します。
JINヘッダー画像にwidth,height,loadingを付与する手順
3つのステップの手順になります。順を追って説明します。
1. あるプラグインをインストール
以下のボタンからダウンロードできるプラグインをダウンロードし、あなたのワードプレスにインストールしてください。プラグインはzipファイルになっています。以下のボタンから無料でダウンロードできます。
ダウンロードしたzipファイルをWordPressの管理画面からアップロードしてインストール有効化します。プラグイン名は「Get Attachment Id」です。詳しいやり方は次の記事をご覧ください。
気になる方のためにお伝えしておくと、このプラグインはこれから行う子テーマに記述する処理で使われる関数を定義しています。子テーマに直接記載しても良かったのですが、この関数は私が作った他のプラグインでも利用しているため、単独のプラグインとして切り出しました。
2. 子テーマのfunction.phpに追記
本手順では子テーマを利用します。子テーマの作り方はネットに情報がたくさんあるので調べてみてください。子テーマのfunctions.phpに以下を追記します。
//make width, height and loading attr by img url.
function make_whl_by_img_url($device = 'pc'){
$url = $device == 'sp' ? get_the_top_image_url_sp() : get_the_top_image_url();
$meta = wp_get_attachment_metadata( get_attachment_id($url));
return image_hwstring($meta['width'], $meta['height']) . 'loading="lazy"';
}
スポンサーリンク
3. 子テーマにheader-image.phpを配置
以下をクリックして表示されるコードを保存してください。
このコードを子テーマ内に
include/head/header-image.php
というパス、ファイル名でアップロードしてください。
パスとファイル名が間違っていると動作しません。これは親テーマ側のパスと対応しています。
これで完了です。Chromeのデベロッパーツールなどであなたのサイトのヘッダー画像のimg要素を確認してみてください。
JINバージョン: 2.650で動作確認。
JIN専用のプラグイン他にも作ってます
JINで使える便利なプラグイン他にも作っていますのでご覧ください。
[card name=jin-more-related-entries]
[card name=jin-blog-card-by-name]
[card name=jin-defer-asset]
[card name=loading-img]
[card name=jin-add-loading-prof-img]
カッテネもおすすめ
ちなみに、3000サイト以上にご利用いただいているカッテネというWordPressプラグインも以前作りました。以下のような商品リンクを作るプラグインです。
こちらはJINはもちろん、それ以外のテーマにも対応しています。また、人気が出たので公式のプラグインとして申請したので、ボタン1つでインストールできます。無料なので使ってみてください。
[card name=make-kattene]
増え続けるプラグイン問題への回答
プラグイン無しにはWordPressの運用はできないと思います。私のように、細かい追加機能を自分でプラグインとしてプラグラミングしてしまう人は当然ですが、そうでない人でも、管理画面のプラグイン一覧に数十個並ぶのも普通なのではないでしょうか。
そうすると、非常に見づらくなり、管理しづらくなります。そこで超役立つプラグインがPlugin Groupsというプラグイン。Pluginをグループに分けられ、グループごとに表示できます。例えば、私が作ったプラグインを複数使っている方なら、「WebFood」などとグループを作ってそれに入れてもいいかもしれません。ちなみに、タグのように複数のグループに所属させることが可能なので、柔軟に分類することができます。ちなみに、これは私の作ったプラグインではなく、公式の方法で簡単にインストールできます。
The post JINのヘッダー画像にwidth,height,loadingを付与する方法 first appeared on WebFood.
]]>The post JINで画像遅延読込時にくるくる画像を表示するプラグイン作った first appeared on WebFood.
]]>サイトやアプリで画像を読み込んでいる時に表示するくるくるする画像ありますよね。あれをJINでも簡単に表示できるようにするプラグインを作りました。
WordPressが画像遅延読込をデフォルト化した
LazyLoading(遅延読込)をデフォルト化したので、ユーザー体験としてはページの表示速度は上がりました。でも、画像が読み込まれるまでは真っ白い空間がだけが表示され、ユーザーは何が起きているかわかりにくいです。
そこにアプリやサイトで画像を読み込んでいる時に表示されるくるくる回る画像が表示されたら、心理的に安心感が出ます。例えばこういう画像です。

簡単にくるくる画像を表示するプラグインを作った
読み込み時にこういうくるくる画像を表示するプラグインを作りました。このプラグインを導入すると、記事上のアイキャッチ画像はこんな感じで読み込まれます。

くるくる画像の色は「カスタマイズ」⇒「カラー設定」⇒「テーマカラー」で設定した色に自動的になります。
一応JIN専用のプラグインですが、get_theme_mod()で'theme_color'に設定している値があるなら、他のテーマでも使えるはずです。
HTMLに画像データを埋め込んだので最速で表示されます
同種のプラグインを見てみたのですが、くるくる画像自体がHTMLとは別のファイルになっていて、読み込みに時間がかかってしまうのが多いです。それに対し、このプラグインは、HTML内にくるくる画像のデータを埋め込んでいるので、ページロード開始からくるくる画像が表示される時間が限りなく短く済みます。
もしよければ、他のと比べてみてください。検証はChromeのデベロッパーツーで遅い通信帯域をエミュレートすると簡単にできます。
アドセンスやYouTubeの読込時にも表示される
imgタグだけでなく、iframeの読込時にも表示するようにしました。なので、埋め込まれたアドセンスやYouTube動画のパーツが読み込まれている間も表示してくれます。
スポンサーリンク
zipファイルをアップロードしてインストール
通常のWordPressプラグインは、WordPressの管理画面でプラグインの新規追加画面で検索してボタン一つか二つ押すだけでインストールできます。しかし、このプラグインはまだ公式のWordPressプラグインとして申請していません。
なので、zipファイルになっているプラグインを入手していただき、それをWordPressの管理画面からアップロードしてインストールする、という方法になります。
zipファイルは以下のボタンから無料でダウンロードできます。
ダウンロードしたzipファイルをWordPressの管理画面からアップロードしてインストールします。プラグイン名は「Loading img」です。詳しいやり方は次の記事をご覧ください。
JINバージョン: 2.650で動作確認。
もしニーズが大きければ
そこまで機能変更があるプラグインでもないので、アップデートする機会はあまりないと思いますが、zipファイルでの手動インストールだと、アップデート時は面倒です。一度プラグインを削除してから、先ほどと同じ手順でインストールする必要があります。
公式のWordPressプラグインとして申請して認められれば、イントールも更新もボタン1つでできるようになります。
もしニーズが大きいようであれば、申請しようと思います。なので、利用してみて使い勝手が良ければ、ブログやSNSでこのプラグインについて紹介してください!
Twitterの場合は、以下の私のアカウントにメンション頂ければ気付きやすいので助かります。またこのプラグインをアップデートした際は、Twitterでお知らせするのでフォロー頂けたら嬉しいです。
https://twitter.com/tai_tantan
JIN専用のプラグイン他にも作ってます
JINで使える便利なプラグイン他にも作っていますのでご覧ください。
[card name=jin-more-related-entries]
[card name=jin-blog-card-by-name]
[card name=jin-defer-asset]
[card name=jin-add-loading-prof-img]
[card name=add-whl-jin-header]
カッテネもおすすめ
ちなみに、3000サイト以上にご利用いただいているカッテネというWordPressプラグインも以前作りました。以下のような商品リンクを作るプラグインです。
こちらはJINはもちろん、それ以外のテーマにも対応しています。また、人気が出たので公式のプラグインとして申請したので、ボタン1つでインストールできます。無料なので使ってみてください。
[card name=make-kattene]
増え続けるプラグイン問題への回答
プラグイン無しにはWordPressの運用はできないと思います。私のように、細かい追加機能を自分でプラグインとしてプラグラミングしてしまう人は当然ですが、そうでない人でも、管理画面のプラグイン一覧に数十個並ぶのも普通なのではないでしょうか。
そうすると、非常に見づらくなり、管理しづらくなります。そこで超役立つプラグインがPlugin Groupsというプラグイン。Pluginをグループに分けられ、グループごとに表示できます。例えば、私が作ったプラグインを複数使っている方なら、「WebFood」などとグループを作ってそれに入れてもいいかもしれません。ちなみに、タグのように複数のグループに所属させることが可能なので、柔軟に分類することができます。ちなみに、これは私の作ったプラグインではなく、公式の方法で簡単にインストールできます。
The post JINで画像遅延読込時にくるくる画像を表示するプラグイン作った first appeared on WebFood.
]]>